The previous two chapters were about linear regression. Linear regression is a type of linear model – recall that in R we used the function lm() to make the regression model. In this chapter we will look at a different type of linear model: analysis of variance (ANOVA).
Introduction
Recall that linear regression is a linear model with one continuous explanatory (independent) variable. A continuous explanatory variable is a variable in which values can take any value within a range (e.g., height, weight, temperature).
In contrast, analysis of variance (ANOVA) is a linear model with one or more categorical explanatory variables. We will first look at a one-way ANOVA, which has one categorical explanatory variable. Later (in a following chapter) we will look at two-way ANOVA, which has two categorical explanatory variables.
What is a categorical variable? A categorical explanatory variable is a variable that contains values that fall into distinct groups or categories. For example, habitat type (e.g., forest, grassland, wetland), treatment group (e.g., control, low dose, high dose), or diet type (e.g., vegetarian, vegan, omnivore).
This means that each observation belongs to one of a limited number of categories or groups. For example, in a study of how blood pressure varies with diet type, diet type is a categorical variable with several levels (e.g., vegetarian, vegan, omnivore). A person can only belong to one diet type category.
Here are the first several rows of a dataset that contains blood pressure measurements for individuals following different diet types:
Rows: 50 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): diet, person_ID
dbl (1): bp
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# A tibble: 6 × 3
bp diet person_ID
<dbl> <chr> <chr>
1 120 meat heavy person_1
2 89 vegan person_2
3 86 vegetarian person_3
4 116 meat heavy person_4
5 115 Mediterranean person_5
6 134 meat heavy person_6
There are three variables: - bp: blood pressure (continuous response variable) - diet: diet type (categorical explanatory variable) - person_ID: unique identifier for each individual (not used in the analysis)
Note that the diet variable is of type <chr> which is short for character. In R, categorical variables are often represented as factors.
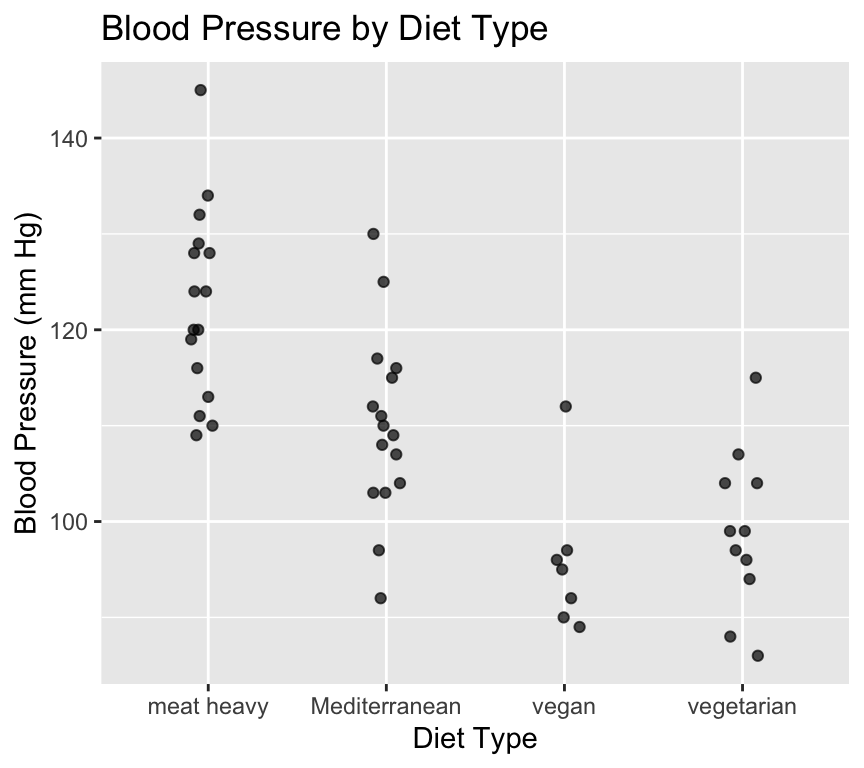
As usual, its a really good idea to visualise the data in as close to “raw” form as possible before doing any analysis. We’ll make a scatterplot of blood pressure versus diet type.
We just used geom_jitter() instead of geom_point() to make a scatterplot. This is because geom_jitter() adds a small amount of random noise to the points, which helps to prevent overplotting when multiple points have the same value (which is common when the x-axis is categorical).
When we use geom_jitter(), we can specify the amount of noise to add in the x and y directions using the width and height arguments, respectively. We must be very careful to not add noise to the y direction if we care about the actual y values (e.g., blood pressure). In this case, we only added noise in the x direction by setting height = 0 to separate the points just enough, but not so much that we could get confused about which of the diets they belong to.
Looking at this graph it certainly looks like diet type has an effect on blood pressure. But is this effect statistically significant? In other words, are the differences in mean blood pressure between diet types larger than we would expect due to random variation alone?
Analysis of variance (ANOVA) is a statistical method that can help us answer this question, and also others.
How does it look like in R?
We can fit a one-way ANOVA model in R using the same lm() function that we used for linear regression. The only difference is that the explanatory variable is categorical.
anova_model <-lm(bp ~ diet, data = bp_data_diet)
Then instead of using summary() to look at the results, we use the anova() function.
anova(anova_model)
Analysis of Variance Table
Response: bp
Df Sum Sq Mean Sq F value Pr(>F)
diet 3 5274.2 1758.08 20.728 1.214e-08 ***
Residuals 46 3901.5 84.82
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
This is an ANOVA table. It shows us the sources of variation in the data, along with their associated degrees of freedom (Df), sum of squares (Sum Sq), mean square (Mean Sq), F value, and p-value (Pr(>F)) associate with a getting a F value the same as or greater than the observed F value if the null hypothesis were true.
The challenge now is to understand what all of these values mean! Let’s take it step by step.
What is ANOVA?
Analysis of variance is a method to compare whether the observations (e.g., of blood pressure) differ according to some grouping (e.g., diet) that the subjects (e.g., people) belong to.
We already know a lot about analysing variance: we compared the total sum of squares (SST), model sum of squares (SSM) and the residual sum of squares (SSE) in the context of linear regression. We used these to calculated the \(R^2\) value. The \(R^2\) value tells us how much of the total variance in the response variable (e.g., blood pressure) is explained by the explanatory variable (e.g., diet).
The same applies to analysis of variance (ANOVA) (as well as regression) because ANOVA is a special case of a linear model, just like regression is also a special case of a linear model.
The defining characteristic of ANOVA is that we are comparing the means of groups by analysing variances. Put another way, we will have a single categorical explanatory variable with two or more levels. We will test whether the means of the response variable are the same across all levels of the explanatory variable, and we test this by analysing the variances.
When we have only one categorical explanatory variable, we use a one-way ANOVA. When we have two categorical explanatory variables, we will use a two-way ANOVA (we’ll look at this in a subsequent chapter).
ANOVA as a linear model
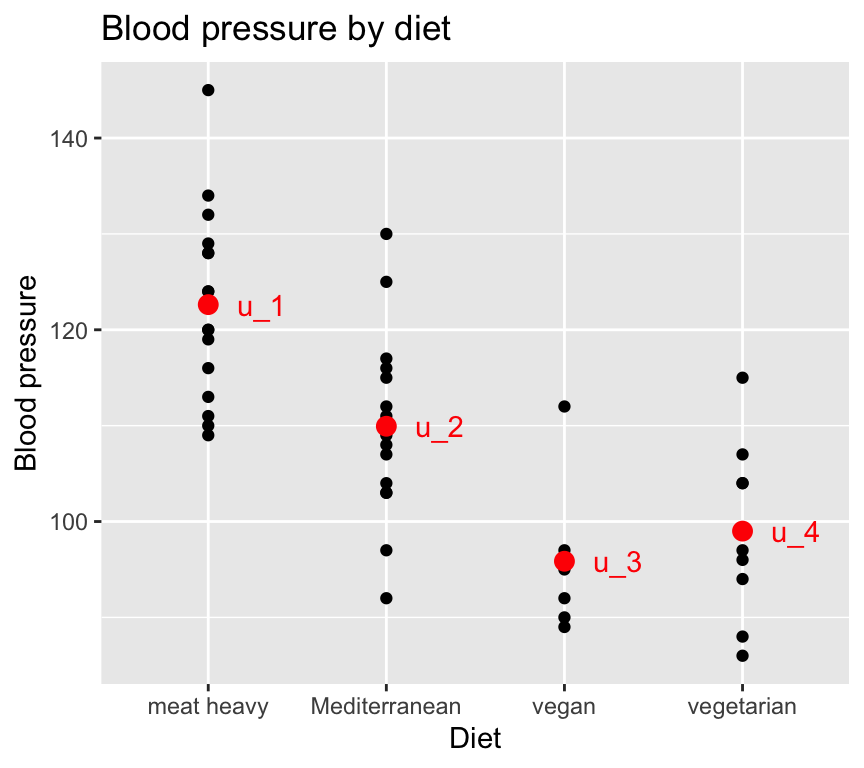
Just like linear regression, ANOVA can be expressed as a linear model. The key difference is that in ANOVA, the explanatory variable is categorical rather than continuous.We formulate the linear model as follows:
\[y_{ij} = \mu_j + \epsilon_{i}\]
where:
\(y_{ij}\) = Blood pressure of individual \(i\) with diet \(j\)
\(\mu_j\) = Mean blood pressure of an individual with diet \(j\)
\(\epsilon_{i}\sim N(0,\sigma^2)\) is an independent error term.
Graphically, with the blood pressure and diet data, this looks like:
Note
There is lots of hidden code used to create the data used in the graph above, and to make the graph itself. You can see the code by going to the Github repository for this book.
Rewrite the model
We usually use a different formulation of the linear model for ANOVA. This is because we usually prefer to express the estimated parameters in terms of differences between means (rather than the means themselves). The reason for this is that then the null hypothesis can be that the differences are zero.
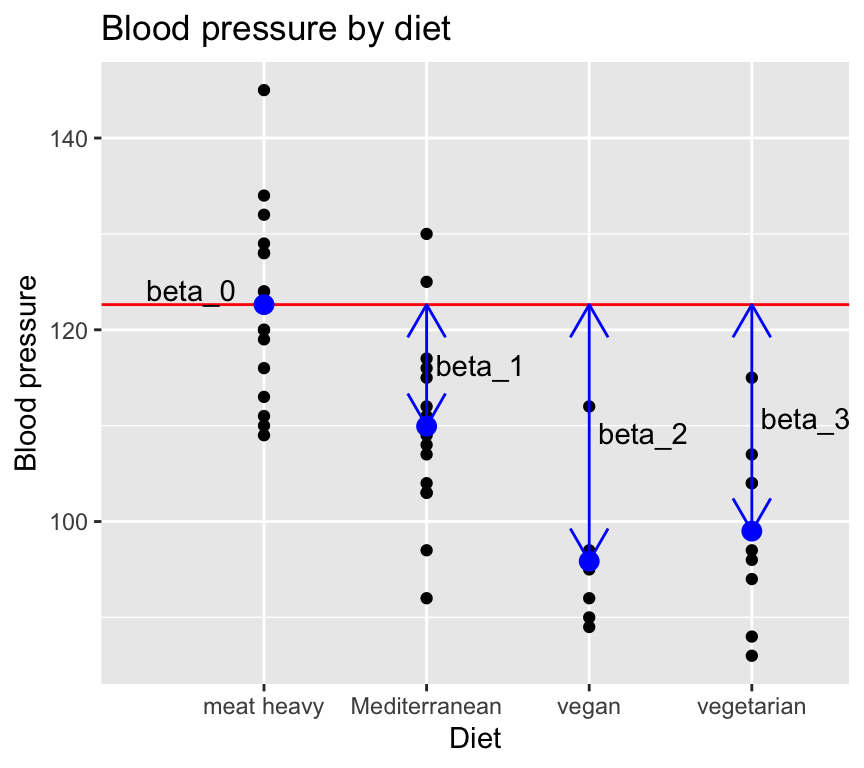
To proceed with this formulation, we define one of the groups as the reference group, and make the mean of that equal to the intercept of the model. For example, if we choose the “meat heavy” diet as the reference group, we can write:
\[\mu_{meat} = \beta_0\]
And then to express the other group means as deviations from the reference group mean:
\[y_i = \beta_0 + \beta_1 x_i^{1} + \beta_2 x_i^{2} + \beta_3 x_i^{3} + \epsilon_i\] where: \(y_i\) is the blood pressure of individual \(i\). \(x_i^{1}\) is a binary variable indicating whether individual \(i\) is on the Mediterranean diet. \(x_i^{2}\) is a binary variable indicating whether individual \(i\) is on the vegan diet. \(x_i^{3}\) is a binary variable indicating whether individual \(i\) is on the vegetarian diet.
Graphically, the model now looks like this:
Here is something to warp you mind… we described one-way ANOVA as a linear model with one categorical explanatory variable. But as you can see above, we can also describe it as a linear model with multiple binary explanatory variables (one for each group except the reference group). And when we make a linear model in R it really does create multiple binary explanatory variables behind the scenes. So one-way ANOVA and multiple linear regression with multiple binary explanatory variables are really the same thing! And, even more mind-warping, one-way ANOVA and multiple regression (regression with multiple continuous explanatory variables) are also the same thing! So when we look at multiple regression later in the course, you can think of it as just an extension of one-way ANOVA.
The ANOVA test: The \(F\)-test
Aim of ANOVA: to test globally if the groups differ. That is we want to test the null hypothesis that all of the group means are equal:
\[H_0: \mu_1=\mu_2=\ldots = \mu_g\] This is equivalent to testing if all \(\beta\)s that belong to a categorical variable are = 0.
\[H_0: \beta_1 = \ldots = \beta_{g-1} = 0\] The alternate hypothesis is that \({H_1}\): The group means are not all the same.
A key point is that we are testing a null hypothesis that concerns all the groups. We are not testing if one group is different from another group (which we could do with a \(t\)-test on one of the non-intercept \(\beta\)s).
Because we are testing a null hypothesis that concerns all the groups, we need to use an \(F\)-test. It asks if the model with the group means is better than a model with just the overall mean.
Note
The \(F\)-test is called the “\(F\)-test” because it is based on the \(F\)-distribution, which was named after the statistician Sir Ronald A. Fisher. Fisher developed this statistical method as part of his pioneering work in analysis of variance (ANOVA) and other fields of experimental design and statistical inference.
Actually, the \(F\)-test does not directly test the null hypothesis that all the group means are equal. Instead, it tests whether the model that includes the group means explains significantly more variance in the data than a model that only includes the overall mean (i.e., without considering group differences).
The \(F\)-test does this by comparing two variance estimates: the variance explained by the group means (between-group variance) and the variance that remains unexplained within each group (within-group variance).
Interpretation of the \(F\) statistic
The \(F\)-test involves calculating from the observed data the value of the \(F\) statistic, and then computing if that value is large enough to reject the null hypothesis.
The \(F\) statistic is a ratio of two variances: the variance between groups, and the variance within groups.
Here is an example with very low within group variability, and high between group variability:
And here’s an example with very high within group variability, and low between group variability:
So, when the ratio of between group variance to within group variance is large, the group means are very different compared to the variability within groups. This suggests that the groups are different.
When the ratio is small, the group means are similar compared to the variability within groups. This suggests that the groups are not different.
\(F\) increases
when the group means become more different, or
when the variability within groups decreases.
\(F\) decreases
when the group means become more similar, or
when the variability within groups increases.
\(\rightarrow\) The larger \(F\), the less likely are the data seen under \(H_0\).
Calculating the \(F\) statistic
Recall that the \(F\) statistic is a ratio of two variances. Specifically, it is the ratio of two mean squares (MS):
\(MS_{model}\): the variability between groups.
\(MS_{residual}\): the variability within groups.
\(MS\) stands for Mean Square, and is a variance estimate.
The \(F\) statistic is calculated as:
\[F = \frac{MS_{model}}{MS_{residual}}\]
To find the mean squares, we need to calculate the within and the between group sums of squares, and the corresponding degrees of freedom. Let’s go though this step by step.
Calculating the sums of squares
First we get the total sum of squares (SST), which quantifies the total variability in the data. This is then split into two parts:
The explained variability, which is known as the between group sum of squares (\(SS_{between}\)) or sum of squares of the model (SSM).
The residual variability, which is known as the within group sum of squares (\(SS_{within}\)) or sum of squares of error / residuals (SSE).
Total variability: SST = \(\sum_{i=1}^k \sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\)
where:
\(y_{ij}\) is the blood pressure of individual \(j\) in group \(i\)
\(\overline{y}\) is the overall mean blood pressure
\(n_i\) is the number of individuals in group \(i\)
And now we need the degrees of freedom for each sum of squares:
SST degrees of freedom: \(n - 1\) (total degrees of freedom is number of observations \(n\) minus 1)
SSM degrees of freedom: \(k - 1\) (model degrees of freedom is number of groups \(k\) minus 1)
SSE degrees of freedom: \(n - k\) (residual degrees of freedom is total degrees of freedom \(n - 1\) minus model degrees of freedom \(k - 1\))
Total degrees of freedom
The total degrees of freedom are the degrees of freedom associated with the total sum of squares (\(SST\)).
In order to calculate the \(SST\), we need to calculate the mean of the response variable. This implies that we estimate one parameter (the mean of the response variable). As a consequence, we lose one degree of freedom and so there remain \(n-1\) degrees of freedom associated with the total sum of squares (where \(n\) is the number of observations).
What do we mean by “lose one degree of freedom”? Imagine we have ten observations. We can calculate the mean of these ten observations. But if we know the mean and nine of the observations, we can calculate the tenth observation. So, in a sense, once we calculate the mean, the value of one of the ten observations is fixed. This is what we mean by “losing one degree of freedom”. When we calculate and use the mean, one of the observations “loses its freedom”.
For example, take the numbers 1, 3, 5, 7, 9. The mean is 5. The sum of the squared differences between the observations and the mean is \((1-5)^2 + (3-5)^2 + (5-5)^2 + (7-5)^2 + (9-5)^2 = 20\). This is the total sum of squares. The degrees of freedom are \(5-1 = 4\).
The total degrees of freedom are the total number of observations minus one. That is, the total sum of squares is associated with \(n-1\) degrees of freedom.
Another perspective in which to think about the total sum of squares and total degrees of freedom is to consider the intercept only model. The intercept only model is a model that only includes the intercept term. The equation of this model would be:
\[y_i = \beta_0 + \epsilon_i\] The sum of the square of the residuals for this model is minimised when the predicted value of the response variable is the mean of the response variable. That is, the least squares estimate of \(\beta_0\) is the mean of the response variable:
\[\hat{\beta}_0 = \bar{y}\]
Hence, the predicted value of the response variable is the mean of the response variable. The equation is:
\[\hat{y}_i = \bar{y} + \epsilon_i\]
The error term is therefore:
\[\epsilon_i = y_i - \bar{y}\] And the total sum of squares is:
\[SST = \sum_{i=1}^n (y_i - \bar{y})^2\]
where \(\hat{y}_i\) is the predicted value of the response variable for the \(i\)th observation, \(\bar{y}\) is the mean of the response variable, and \(\epsilon_i\) is the residual for the \(i\)th observation.
The intercept only model involves estimating only one parameter, so the total degrees of freedom are the total number of observations minus one \(n - 1\).
Therefore, the total degrees of freedom are the total number of observations minus one.
Bottom line: \(SST\) is the residual sum of squares when we fit the intercept only model. The total degrees of freedom are the total number of observations minus one.
Model degrees of freedom
The model degrees of freedom are the degrees of freedom associated with the model sum of squares (\(SSM\)).
In the case of the intercept only model, we estimated one parameter, the mean of the response variable.
In the case of a categorical variable with \(k\) groups, we need \(k-1\) parameters (non intercept \(\beta\) parameters), so we lose \(k-1\) degrees of freedom. Put another way, when we fit a model with a categorical explanatory variable with \(k\) groups, we estimate \(k-1\) parameters in addition to the intercept. That is, we estimate the difference between each group and the reference group.
Each time we estimate a new parameter, we lose a degree of freedom.
Residual degrees of freedom
The residual degrees of freedom are the total degrees of freedom (\(n-1\)) minus the model degrees of freedom (\(k-1\)).
Therefore, the residual degrees of freedom are the degrees of freedom remaining after we estimate the intercept and the other \(\beta\) parameters. There is one intercept and \(k-1\) other \(\beta\) parameters, so the residual degrees of freedom are \(n-1- ( k-1) = n - k\).
Calculating the mean square and \(F\) statistic
From these sums of squares and degrees of freedom we can calculate the mean squares and \(F\)-statistic:
Why divide by the degrees of freedom? The more observations we have, the greater will be the total sum of squares. The more observations we have, the greater will be the residual sum of squares. So it is not very informative to compare totals. Rather, we need to compare the mean of the sums of squares. Except we don’t calculate the mean by dividing by the number of observations. Rather we divide by the degrees of freedom. The total mean square is an estimate of the variance of the response variable. And the residual mean square is an estimate of the variance of the residuals.
\(SST\), \(SSM\), \(SSE\), and degrees of freedom
Just a reminder and a summary of some of the material above:
\(SST\): degrees of freedom = \(n-1\)
\(SSM\): degrees of freedom = \(k-1\)
\(SSE\): degrees of freedom = \(n-k\)
The sum of squares add up:
\[SST = SSM + SSE\]
and the degrees of freedom add up
\[(n-1) = (k-1) + (n - k)\]
Source of variance table
Now we have nearly everything we need. We often express all of this (and a few more quantities) in a convenient table called the sources of variance table (or ANOVA table).
The sources of variance table is a table that conveniently and clearly gives all of the quantities mentioned above. It breaks down the total sum of squares into the sum of squares explained by the model and the sum of squares due to error. The source of variance table is used to calculate the \(F\)-statistic.
Sources of variance table
Source
Sum of squares
Degrees of freedom
Mean square
F-statistic
Model
\(SSM\)
\(k-1\)
\(MSE_{model} = SSM / k-1\)
\(\frac{MSE_{model}}{MSE_{error}}\)
Error
\(SSE\)
\(n - 1 - (k-1)\)
\(MSE_{error} = SSE / (n - 1 - (k-1))\)
Total
\(SST\)
\(n - 1\)
Is my \(F\)-statistic large or small?
OK, so we have calculated the \(F\) statistic. But how do we use it to test our hypothesis?
We can use the \(F\) statistic to calculate a \(p\)-value, which tells us how likely our data is under the null hypothesis.
Some key points:
\(F\)-Distribution: The test statistic of the \(F\)-test (that is, the \(F\)-statistic) follows the \(F\)-distribution under the null hypothesis. This distribution arises when comparing the ratio of two independent sample variances (or mean squares).
Ronald Fisher’s Contribution: Fisher introduced the \(F\)-distribution in the early 20th century as a way to test hypotheses about the equality of variances and to analyze variance in regression and experimental designs. The “\(F\)” in \(F\)-distribution honours him.
Variance Ratio: The test statistic for the \(F\)-test is the ratio of two variances (termed mean squares in this case), making the \(F\)-distribution the natural choice for modeling this ratio when the null hypothesis is true.
The \(F\)-test is widely used, including when comparing variances, assessing the significance of multiple regression models (see later chapter), conducting ANOVA to test for differences among group means, and for comparing different models.
Recall that “The \(F\)-statistic is calculated as the ratio of the mean square error of the model to the mean square error of the residuals.” And that a large \(F\)-statistic is evidence against the null hypothesis that the slopes of the explanatory variables are zero. And that a small \(F\)-statistic is evidence to not reject the null hypothesis that the slopes of the explanatory variables are zero.
But how big does the F-statistic need to be in order to confidently reject the null hypothesis?
The null hypothesis that the explained variance of the model is no greater than would be expected by chance. Here, “by chance” means that the slopes of the explanatory variables are zero.
\[H_0: \beta_1 = \beta_2 = \ldots = \beta_p = 0\]
The alternative hypothesis is that the explained variance of the model is greater than would be expected by chance. This would occur if the slopes of some or all of the explanatory variables are not zero.
\[H_1: \beta_1 \neq 0 \text{ or } \beta_2 \neq 0 \text{ or } \ldots \text{ or } \beta_p \neq 0\]
To test this hypothesis we are going to, as usual, calculate a \(p\)-value. The \(p\)-value is the probability of observing a test statistic as or more extreme as the one we observed, assuming the null hypothesis is true. To do this, we need to know the distribution of the test statistic under the null hypothesis. The distribution of the test statistic under the null hypothesis is known as the \(F\)-distribution.
The \(F\)-distribution has two degrees of freedom values associated with it: the degrees of freedom of the model and the degrees of freedom of the residuals. The degrees of freedom of the model are the number of parameters estimated by the model corresponding to the null hypothesis. The degrees of freedom of the residuals are the total degrees of freedom minus the degrees of freedom of the model.
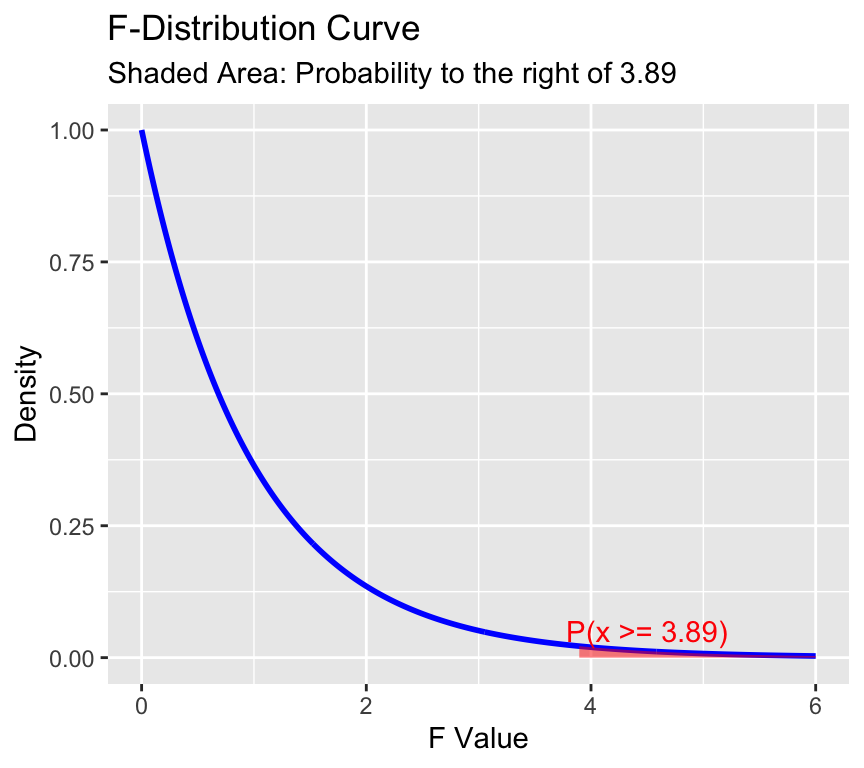
Here is the \(F\)-distribution with 2 and 99 degrees of freedom:
The F-distribution is skewed to the right and has a long tail. The area to the right of 3.89 is shaded in red. This area represents the probability of observing an F-statistic as or more extreme as 3.89, assuming the null hypothesis is true. This probability is the \(p\)-value of the hypothesis test.
The \(F\)-statistic and \(F\)-test uses the fact that:
follows an \(F\)-distribution with \(k-1\) and \(n-k\) degrees of freedom, where \(k\) is the number of groups in the categorical variable, and \(n\) the number of data points.
\(SSE=\sum_{i=1} ^n(y_i-\hat{y}_i)^2\) is the residual sum of squares
\(SSM = SST - SSE\) is the sum of squares of the model
\(SST=\sum_{i=1}^n(y_i-\overline{y})^2\) is the total sum of squares
\(n\) is the number of data points
\(k\) is the number of groups in the categorical variable
Well, that is ANOVA conceptually. But how does it actually look like in R?
Doing ANOVA in R
Let’s go back again the question of how diet effects blood pressure. Here is the data:
# A tibble: 6 × 3
bp diet person_ID
<dbl> <chr> <chr>
1 120 meat heavy person_1
2 89 vegan person_2
3 86 vegetarian person_3
4 116 meat heavy person_4
5 115 Mediterranean person_5
6 134 meat heavy person_6
ggplot(bp_data_diet, aes(x = diet, y = bp)) +geom_point() +labs(title ="Blood pressure by diet",x ="Diet",y ="Blood pressure")
And here is how we fit a linear model to this data:
fit <-lm(bp ~ diet, data = bp_data_diet)
IMPORTANT: Since ANOVA is a linear model, it is important to check the assumptions of linear models before interpreting the results. These are some of the same assumptions we checked for simple linear regression, including: independence of errors, normality of residuals, and homoscedasticity (constant variance of residuals).
As with linear regression, we check the assumptions are not too badly broken by looking at model checking plots:
autoplot(fit, which =1:4, add.smooth =FALSE)
The Q-Q plot (top right) looks pretty good, indicating that the residuals are approximately normally distributed.
The residuals vs fitted plot (top left) does not show any clear pattern, which is good (though since there is no continuous explanatory variable, we would not expect to see a pattern in this plot).
The scale-location plot (bottom left) does not show any clear pattern, which is good. This suggests that the residual variance is not different in different groups, i.e., that there is little if any heteroscedasticity.
The residuals vs leverage plot (bottom right) does not show any clear pattern, which is good. Note that there is no measurement of the leverage of the data points in the plot above. This is because there are no continuous explanatory variables in the model. The leverage of a data point is a measure of how much that data point influences the fitted values of the model. In a linear regression model with continuous explanatory variables, the leverage of a data point can be calculated based on its distance from the mean of the explanatory variables. However, in an ANOVA model with only categorical explanatory variables, the leverage of each data point is determined solely by its group membership and is not influenced by any continuous variables. Therefore, there is no need to calculate or display leverage in this case.
There are a few residuals that might be a bit extreme. These might be worth investigating, but we will ignore them for now.
Now we can look at the ANOVA table:
anova(fit)
Analysis of Variance Table
Response: bp
Df Sum Sq Mean Sq F value Pr(>F)
diet 3 5274.2 1758.08 20.728 1.214e-08 ***
Residuals 46 3901.5 84.82
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The ANOVA table shows the sum of squares, degrees of freedom, mean square, F value, and p-value for the model and residuals. As we know, the \(F\) value (\(F\) statistics) is calculated as the mean square of the model divided by the mean square of the residuals. The p-value is calculated based on the F-distribution with the appropriate degrees of freedom.
A suitable sentence to report our findings would be: “Diet has a significant effect on blood pressure (\(F(2, 27) = 20.7, p < 0.0001\))”. This means that the probability of observing such a large \(F\) value under the null hypothesis is less than 0.01%.
Difference between pairs of groups
If, and only if the \(F\)-test is significant, we can conclude that there is a significant difference between the groups. But this does not tell us which groups differ from each other.
If we’d like to know which pairs of groups differ, we have a few issues to contend with.
ANOVA does not tell us this!
Controlling error rates.
Let’s first look at error rates.
Error-rates
Imagine a fire alarm that goes off when there is a fire. The alarm can make two types of errors:
Type I error: The alarm goes off when there is no fire (false positive).
Type II error: The alarm does not go off when there is a fire (false negative).
In the context of hypothesis testing, a Type I error occurs when we reject the null hypothesis when it is actually true. A Type II error occurs when we fail to reject the null hypothesis when it is actually false.
When we decide that p < 0.05 is the threshold for “significance”, we are essentially saying that we are willing to accept a 5% chance of making a Type I error. That is, we are willing to accept a 5% chance of rejecting the null hypothesis when it is actually true.
So when we do one test, e.g., and F-test, and use 0.05 as the threshold \(p\) for significance, we are setting a per test error rate of 0.05.
What happens is we do multiple tests, each with an 0.05 threshold (i.e., 0.05 type 1 error rate)? The more tests we do, the more likely we are to make at least one Type I error. This is known as the problem of multiple comparisons / tests.
To illustrate this, imagine that we have a fire alarm that goes off 5% of the time when there is no fire (i.e., it has a 5% false positive rate). Imagine that we test the alarm 100 times when there is no fire. On average, we would expect the alarm to go off 5 times (5% of 100) just by chance, even though there is no fire in any test. This illustrates the problem of doing multiple tests: the more tests we do, the more likely we are to get a false positive just by chance.
To illustrate this in the context of ANOVA, imagine that we have 10 groups, and we want to test if any pairs of groups differ from each other. This would involve making 45 pairwise comparisons (since there are \(\binom{10}{2} = 45\) pairs of groups). If we use a significance threshold of 0.05 for each individual test, we would expect to get about 2.25 false positives just by chance (5% of 45). This means that even if there were no true differences between the groups, we would still expect to find just over two significantly different pairs, even when there really is no significant difference.
Going a little further, we can calculate something called the family-wise error rate (FWER), which is the probability of making at least one Type I error across all the tests. The FWER can be calculated as:
\[FWER = 1 - (1 - \alpha)^m\]
where \(\alpha\) is the per test error rate (e.g., 0.05) and \(m\) is the number of tests (e.g., 45). In our example, the FWER would be:
\[FWER = 1 - (1 - 0.05)^{45} \approx 0.90\]
Yes, you read that right! In this example, with 45 pairwise comparisons and a per test error rate of 0.05, the family-wise error rate is about 90%. This means that there is a 90% chance of making at least one Type I error across all 45 tests, even if there are no true differences between the groups. It is almost certain that we will find at significant difference even though there is no real difference!
So, when we want to find which pairs of groups differ, we cannot just do lots of \(t\)-tests and look for significant results. We need to use a method that takes into account the problem of multiple comparisons.
ANOVA doesn’t compare pairs
The second issue is that ANOVA does not itself compare any pairs of groups. Rather, it works by doing an \(F\) test. This tests the null hypothesis that all group means are equal. It does not tell us which groups are different from each other. It just tells us that fitting group means explains a significant amount of variance in the data.
In fact, we can find a significant \(F\)-statistic even when none of the pairs of groups are significantly different (e.g., when tested with a \(t\)-test). And we can find the opposite, a non-significant \(F\)-statistic even when one of the pairs of groups is significantly different by \(t\)-test.
Comparing pairs of groups
The solution to both issues is to use a method that allows us to compare pairs of groups while controlling for the problem of multiple comparisons. There are several methods to do this. The most prominent ones are:
Fisher Least Significant Differences (LSD) approach
The second two when implemented in R also provide all possible pairwise comparisons.
Bonferroni correction
If we find a significant \(F\)-statistic, we can then proceed to compare pairs of groups while controlling for the problem of multiple comparisons. One method to do this is the Bonferroni correction.
The idea here is to control the family-wise error rate by adjusting the per test error rate. The Bonferroni correction is a simple method to control the family-wise error rate when performing multiple comparisons. It works by adjusting the significance threshold for each individual test to account for the number of tests being performed.
If a total of \(m\) tests are carried out, simply divide the per test type-I error level \(\alpha_0\) (often 5%) by the number of tests:
\[\alpha = \alpha_0 / m \ .\] This gives the FWER as:
With the previous example of 45 pairwise comparisons and a per test error rate of 0.05, the Bonferroni correction would adjust the per test error rate to:
\[\alpha = 0.05 / 45 \approx 0.0011\]
And the FWER would be:
\[FWER = 1 - (1 - 0.0011)^{45} \approx 0.05\]
Note that an equivalent method to control the family-wise error rate is to adjust the p-values of the individual tests instead of adjusting the significance threshold. The Bonferroni correction can also be applied by multiplying the p-values of the individual tests by the number of tests. If the adjusted p-value is less than the original significance threshold (e.g., 0.05), then we reject the null hypothesis for that test.
We can quickly get all the pairwise comparisons with the Bonferroni correction by using the pairwise.t.test function in R. This function performs pairwise t-tests between groups and applies the specified p-value adjustment method to control for multiple comparisons.
Pairwise comparisons using t tests with pooled SD
data: bp_data_diet$bp and bp_data_diet$diet
meat heavy Mediterranean vegan
Mediterranean 0.0019 - -
vegan 4.2e-07 0.0091 -
vegetarian 2.6e-07 0.0239 1.0000
P value adjustment method: bonferroni
There are six pairwise comparisons (since there are four groups, and \(\binom{4}{2} = 6\) pairs of groups). The output shows the p-values for each pairwise comparison after applying the Bonferroni correction. We can see that all pairwise comparisons have a p-value less than 0.05, except for the comparison of vegan versus vegetarian, which has a p-value that rounds to 1.0000.
Let’s check our understanding of the Bonferroni adjustment to the p-values. The adjusted p-value for the Mediterranean versus vegetarian comparison is 0.0239. There are six tests in total. So the unadjusted p-value for this comparison would be \(0.0239 / 6 \approx 0.0040\). Let’s check this by asking for the unadjusted p-values:
Pairwise comparisons using t tests with pooled SD
data: bp_data_diet$bp and bp_data_diet$diet
meat heavy Mediterranean vegan
Mediterranean 0.00031 - -
vegan 6.9e-08 0.00151 -
vegetarian 4.3e-08 0.00398 0.48386
P value adjustment method: none
Yes, the unadjusted p-value for the Mediterranean versus vegetarian comparison is 0.004, which matches our calculation. The Bonferroni correction has adjusted this p-value to 0.0239 to control for the family-wise error rate across all six comparisons.
Tukey HSD approach
Another approach to comparing group means after ANOVA is Tukey’s Honest Significant Difference (HSD) method. In this approach, we first perform the ANOVA F-test. Only if the F-test is significant do we proceed to compare pairs of group means.
Instead of adjusting each test separately, it treats all pairwise comparisons as one set of comparisons and calculates a single threshold for differences between group means that keeps the overall false-positive rate at the chosen level. In practice, this means Tukey HSD determines how large a difference between two means must be before we consider it significant, given the number of groups being compared.
In short, Bonferroni adjusts the significance threshold for each test, while Tukey HSD directly determines the minimum difference between group means needed to declare a significant pairwise difference while controlling the overall error rate.
In R we can use the multcomp package to do Tukey HSD tests:
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: lm(formula = bp ~ diet, data = bp_data_diet)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
Mediterranean - meat heavy == 0 -12.688 3.256 -3.897 0.00168 **
vegan - meat heavy == 0 -26.768 4.173 -6.414 < 0.001 ***
vegetarian - meat heavy == 0 -23.625 3.607 -6.549 < 0.001 ***
vegan - Mediterranean == 0 -14.080 4.173 -3.374 0.00759 **
vegetarian - Mediterranean == 0 -10.938 3.607 -3.032 0.01951 *
vegetarian - vegan == 0 3.143 4.453 0.706 0.89305
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- single-step method)
We get all the pairwise comparisons, along with their estimates, standard errors, t-values, and p-values. We also get a note Adjusted p values reported -- single-step method, indicating that the Tukey HSD adjustment has been applied to the p-values.
Again, all pairwise comparisons have a p-value less than 0.05, except for the comparison of vegan versus vegetarian, which has a p-value of 0.89305.
Fisher’s LSD approach
Another approach to comparing group means after ANOVA is Fisher’s Least Significant Difference (LSD) method. In this approach, we first perform the ANOVA F-test. Only if the F-test is significant do we proceed to compare pairs of group means.
In the Fisher LSD approach, we use a two-sample test, but use a larger variance (namely the pooled variance of all groups) that we would use in a two-sample test. This is because we are using the same variance estimate for all pairwise comparisons, which is the mean square error from the ANOVA.
Which method to use?
The Bonferroni correction is more conservative than Tukey HSD, which is more conservative than Fisher LSD. The Bonferroni correction is less powerful than Tukey HSD, which is less powerful than Fisher LSD. So if we want to be more confident that we are not making any false positives, we can use the Bonferroni correction. If we want to be more confident that we are not missing any true positives, we can use the Fisher LSD approach. The Tukey HSD approach is a good middle ground between the two.
Other contrasts
A contrast is a specific comparison between groups. So far we have only considered pairwise contrasts (i.e., comparing two groups at a time). But we can also design more complex contrasts. For example: are diets that contain meat different from diets that do not contain meat?
bp_data_diet <-mutate(bp_data_diet,meat_or_no_meat =ifelse(diet =="meat"| diet =="Mediterranean","meat", "no meat"))head(bp_data_diet)
# A tibble: 6 × 4
bp diet person_ID meat_or_no_meat
<dbl> <fct> <chr> <chr>
1 120 meat heavy person_1 no meat
2 89 vegan person_2 no meat
3 86 vegetarian person_3 no meat
4 116 meat heavy person_4 no meat
5 115 Mediterranean person_5 meat
6 134 meat heavy person_6 no meat
Here we defined a new explanatory variable that groups the meat heavy and Mediterranean diet together into a single “meat” group and vegetarian and vegan into a single “no meat” group. We then fit a model with this explanatory variable:
fit_mnm <-lm(bp ~ meat_or_no_meat, data = bp_data_diet)
(We should not look at model checking plots here, before using the model. But let us continue as if the assumptions are sufficiently met.)
We now do something a bit more complicated: we compare the variance explained by the model with four diets to the model with two diets. This is done by comparing the two models using an \(F\)-test. We are testing the null hypothesis that the two models are equally good at explaining the data, in which case the two diet model will explain as much variance as the four diet model.
Let’s look at the ANOVA table of the model comparison:
anova(fit, fit_mnm)
Analysis of Variance Table
Model 1: bp ~ diet
Model 2: bp ~ meat_or_no_meat
Res.Df RSS Df Sum of Sq F Pr(>F)
1 46 3901.5
2 48 9173.4 -2 -5271.9 31.078 2.886e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
We see the residual sum of squares of the model with meat or no meat is over 9’000, while that of the four diet model is less than 4’000. That is, the four diet model explains much more variance in the data than the two diet model. The \(F\)-test is highly significant, so we reject the null hypothesis that the two models are equally good at explaining the data. And we conclude that its not just whether people eat meat or not, but rather what kind of diet they eat that affects their blood pressure.
Ideally we do not make a lot of contrasts after we have collected and looked at our data. Rather, we would specify the contrasts we are interested in before we collect the data. This is called a priori contrasts. But sometimes we do exploratory data analysis and then we can make post hoc contrasts. In this case we should be careful to adjust for multiple comparisons.
Review
Here are the key points from this chapter:
ANOVA is just another linear model.
It is used when we have categorical explanatory variables.
We use \(F\)-tests to test the null hypothesis of no difference among the means of the groups (categories).
We can use contrasts and post-hoc tests to test specific hypotheses about the means of the groups.
Further reading
If you’d like some further reading on ANOVA and ANOVA in R, here are some good resources. There is lots of overlap among them, however, and with the material in this chapter. I suggest to look at them mostly for different perspectives and examples. And only if you’d like to solidify your understanding.
Chapter 5, Section 5.6, of Getting Started with R by Beckerman et al. This section is about 10 pages.
Chapter 11 of The New Statistics with R by Hector, not including the section on two-way ANOVA. This chapter is about 10 pages.
Chapter 14 of Linear Models with R by Faraway. This chapter is eight pages.
Chapter 9 of Statistics. An Introduction using R by Crawley, up to the section Factorial experiments. This section is about 16 pages.
Extras
Choosing the reference category
Question: Why was the “heavy meat” diet chosen as the reference (intercept) category?
Answer: Because R orders the categories alphabetically and takes the first level alphabetically as reference category.
Sometimes we may want to override this, for example if we have a treatment that is experimentally the control, then it will usually be useful to set this as the reference / intercept level.
In R we can set the reference level using the relevel function:
And now make the model and look at the estimated coefficients:
fit_vegan_ref <-lm(bp ~ diet, data = bp_data_diet)summary(fit_vegan_ref)
Call:
lm(formula = bp ~ diet, data = bp_data_diet)
Residuals:
Min 1Q Median 3Q Max
-17.9375 -5.9174 -0.4286 5.2969 22.3750
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 95.857 3.481 27.538 < 2e-16 ***
dietmeat heavy 26.768 4.173 6.414 6.92e-08 ***
dietMediterranean 14.080 4.173 3.374 0.00151 **
dietvegetarian 3.143 4.453 0.706 0.48386
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.21 on 46 degrees of freedom
Multiple R-squared: 0.5748, Adjusted R-squared: 0.5471
F-statistic: 20.73 on 3 and 46 DF, p-value: 1.214e-08
Now we see the estimated coefficients for all diets except the vegan diet. The intercept is the mean individuals with vegan diet.
Communicating the results of ANOVA
When communicating the results of an ANOVA, we usually report the \(F\)-statistic, the degrees of freedom of the numerator and denominator, and the p-value. For example, we could say:
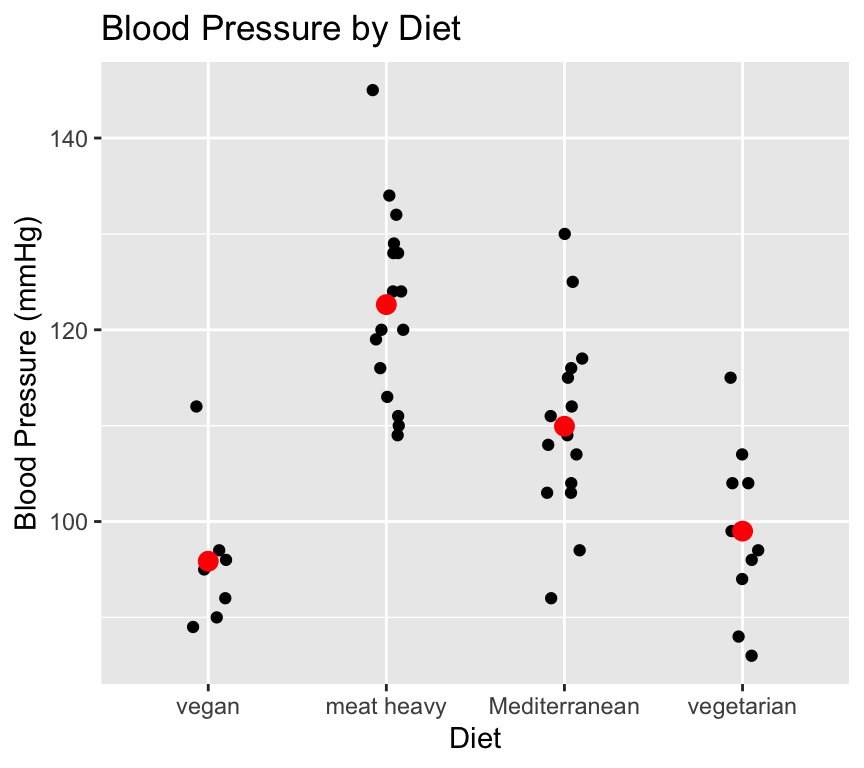
Blood pressure differed significantly between groups, with the mean of a meat heavy diet being 123 mmHg, while the mean blood pressure of the vegan group was 27 mmHg lower (One-way ANOVA, \(F(3, 46) = 20.7\), \(p < 0.0001\).
And we would make a nice graph, in this case showing each individual observation since there are not too many to cause overplotting. We can also add the estimated means of each group if we like:
ggplot(bp_data_diet, aes(x = diet, y = bp)) +geom_jitter(width =0.1, height =0) +stat_summary(fun = mean, geom ="point", color ="red", size =3) +labs(title ="Blood Pressure by Diet",x ="Diet",y ="Blood Pressure (mmHg)")
Some people like to see error bars as well, for example showing the 95% confidence intervals of the means:
ggplot(bp_data_diet, aes(x = diet, y = bp)) +geom_jitter(width =0.1, height =0, col ="grey") +stat_summary(fun = mean, geom ="point", color ="black", size =3) +stat_summary(fun.data = mean_cl_normal, geom ="errorbar", width =0.2, color ="black") +labs(title ="Blood Pressure by Diet\nBlack points and error bars show mean ± 95% CI",x ="Diet",y ="Blood Pressure (mmHg)")
There are many many plotting styles and preferences. The important thing is to clearly communicate the results, and to not mislead the reader. I find that plotting the individual data points is often a good idea, especially when the sample size is not too large.
ANOVA and experimental design
This is not a course about experimental design (this is much too large a subject to cover). You may have noticed, however, that all of the example datasets and questions in your reading about ANOVA have been manipulative experiments, where researchers had various treatment groups containing the experimental subjects. That is, the researchers manipulated something to be different among the groups, and looked for any evidence of resulting differences.
This might lead you to wonder if we always analyse manipulative experiments with ANOVA, and always analyse observational studies (involving no manipulations) with regression. The answer is no, we can use either for either. It just happens that manipulations in experiments are often of the categorical nature: type of food, parasite species, light level (high or low), and so on. Of course some experiments contain manipulations that are continuous (e.g. a range of temperatures or drug concentrations) and these are analysed with regression. And some studies include a manipulation (e.g., drug concentration) and observed variables like gender.
So there isn’t necessarily an association between type of explanatory variable (continuous or categorical) and whether a study is experimental or observational. Essential is for the researcher to clearly be aware of which variables are manipulation and which are observations. Because only the manipulations can be used to infer causation.