# This is a comment. Comments are ignored by R.
# They are useful for explaining what your code does.R and RStudio (L2)
Getting R and RStudio
R is a programming language and software environment for statistical computing and graphics. RStudio is an integrated development environment (IDE) for R. RStudio provides a user-friendly interface for working with R, including a console, a script editor, and tools for managing packages and projects.
We highly recommend using RStudio to work with R.
There are two ways to use RStudio:
RStudio Desktop: a standalone application that you can install on your computer. If you choose this option, you will need to install R first, and then install RStudio. This usually requires administrator privileges on your computer. If you have problems installing add-on packages, they will have to be fixed by you or with our help (rarely we cannot find a solution). Follow the instructions on this website about how to install R and RStudio: https://posit.co/download/rstudio-desktop/.
Rstudio Cloud: a web-based version of RStudio that you can use in your web browser. You don’t need to install anything on your computer, and you can access your work from any computer with an internet connection. The Faculty of Science has a RStudio Cloud here that you can use (and will have to use during the final exam).
What do we recommend? Try the cloud first. If you like it then continue to use it.
Important
Whether you use the RStudio application on your computer, or use RStudio on the Cloud, you are responsible for the safety and persistence of your files (data, code, etc.). Just because you’re using RStudio on the Cloud does not mean your files are automatically saved forever. Make sure to download and back up your important files regularly!
Getting to know the RStudio IDE
When you open RStudio, you will see a window with four main panes:
- Source pane: where you can write and edit R scripts, R Markdown documents, and other files. This pane can have multiple tabs, so you can have several files open at the same time.
- Console pane: where you can type and execute R commands directly. This pane has multiple tabs, including: Console, Terminal, and Jobs. During this course we will mostly use the Console tab.
- Environment pane: where you can see the objects (data frames, vectors, etc.) that are currently in your R session. This pane has multiple tabs, including: Environment, History, Connections, and Tutorial. During this course we will mostly use the Environment tab.
- Files/Plots/Packages/Help pane: where you can manage files, view plots, manage packages, and access help documentation. This pane has multiple tabs, including: Files, Plots, Packages, Help, and Viewer. During this course we will mostly use the Files, Plots, Packages, and Help tabs.
Our Scripts are in the Source pane tabs. The code / script we write in R is usually saved in a file with the extension .R. This file can be opened and edited in the Source pane. Creating a new R script: File > New File > R Script.
You can run code from the script by selecting the code and clicking the “Run” button, or by using the keyboard shortcut Ctrl + Enter (Windows) or Cmd + Enter (Mac).
There is so much more to learn about the RStudio IDE, but we will cover that as we go along in the course.
Getting to know R
In our newly opened script file, type the following code:
Then type the following code:
1 + 1[1] 2exp(2)[1] 7.389056sqrt(16)[1] 4Select all the code and run it (using the “Run” button or Ctrl + Enter / Cmd + Enter). You should see the results of the calculations in the Console pane.
Now try assigning values to named object:
a <- 5
b <- 10
c <- a + b
Note
In fact, just about everything in R is an object! These objects live in your R session (i.e., in the memory of your computer), and you can see them in the Environment pane. You can create objects to store data, functions, and other information. Your data files are something different. They are just like other files on your computer, such as documents, images, and music files. They live on your hard drive (or in the cloud), and you can import them into R when you need to work with them.
And then print the value of c:
c[1] 15You should see the value 15 printed in the Console pane.
We can also create vectors:
my_vector <- c(1, 2, 3, 4, 5)
my_vector[1] 1 2 3 4 5And do maths on vectors:
my_vector * 2[1] 2 4 6 8 10my_vector + 10[1] 11 12 13 14 15my_vector ^ 2[1] 1 4 9 16 25We can vectors of strings (text):
my_strings <- c("apple", "banana", "cherry")
my_strings[1] "apple" "banana" "cherry"And can perform operations on strings:
paste("I like", my_strings)[1] "I like apple" "I like banana" "I like cherry"toupper(my_strings)[1] "APPLE" "BANANA" "CHERRY"And we can create data frames, which are like tables of data
my_data <- data.frame(
Name = c("Alice", "Bob", "Charlie"),
Age = c(25, 30, 35),
Height = c(165, 180, 175)
)
my_data Name Age Height
1 Alice 25 165
2 Bob 30 180
3 Charlie 35 175Above we have numerous examples of functions: exp(), sqrt(), c(), paste(), toupper(), and data.frame(). Functions are a fundamental part of R programming. They are used to perform specific tasks, such as calculations, data manipulation, and data analysis. All functions have a name and can take arguments (inputs) and return values (outputs). They are called by writing the function name followed by parentheses, with any arguments inside the parentheses.
You likely guessed that there is much much more to learn about R, but we will cover that as we go along in the course.
Getting help
R has a built-in help system that you can use to get information about functions, packages, and other topics. To access the help system, you can use the ? operator followed by the name of the function or topic you want to learn about. For example, to get help on the mean() function, you would type:
?meanThis will open the help documentation for the mean() function in the Help pane of RStudio. The documentation includes a description of the function, its arguments, and examples of how to use it. Some of the help documentation is very useful and accessible, other is less so. Over time you will learn which functions and packages have good documentation, and you will get better and better at understanding R help files.
Of course you can use any other resources to get help with R, including online forums, tutorials, and books. Some popular online resources for R help include:
You can also use search engines like Google to find answers to your R questions. Just be sure to include “R” in your search query to get relevant results.
AI assistants like ChatGPT can also be useful for getting help with R programming. You can ask specific questions about R code, functions, and packages, and get instant responses.
And of course there is always your course instructors and fellow students to help you out when you get stuck.
Add-on packages
R has a vast ecosystem of add-on packages that extend its functionality. These packages are collections of functions, data, and documentation that can be installed and loaded into your R session. There are thousands of packages available on CRAN (the Comprehensive R Archive Network) and other repositories like Bioconductor and GitHub.
We will be using several packages throughout this course. To install a package, you can use the install.packages() function. For example, to install the ggplot2 package, you would type:
install.packages("ggplot2")You can also use the RStudio interface to install packages. Go to the “Packages” tab in the bottom right pane, click on “Install”, type the name of the package you want to install, and click “Install”.
You can see which packages are currently installed by looking in the “Packages” tab.
Tip
You only need to install a package once. After it is installed, you can load it into your R session using the library() function. Do not install packages every time you want to use them; just load them with library().
R Version and add-on package versions
(This section concerns the Desktop version of R and RStudio, and not so much the Cloud version, because version management is handled for you in the Cloud.)
R and its add-on packages are constantly being updated and improved. This can cause problems when trying to install or use packages that depend on specific versions of R or other packages.
Imagine that the online version of a package has been updated and now only works with the lastest version of R. If you are using an older version of R, you may not be able to install or use that package.
Or if a package depends on another package that has been updated, you may need to update that package as well to use the first package.
This sounds complicated, but there are some simple steps you can take to reduce the chances of running into version-related problems:
Keep your R version up to date. New versions of R are released every 6 months or so, and they often include important bug fixes and new features. You can check your current R version by typing
R.version.stringin the Console. To update R, you can download the latest version from the CRAN website.Keep your add-on packages up to date. You can update all your installed packages by using the
update.packages()function. This will check for updates for all installed packages and install the latest versions. You can also use the RStudio interface to update packages by going to the “Packages” tab, clicking on “Update”, selecting the packages you want to update, and clicking “Install Updates”.Do this well before critical deadlines or important events (e.g., exams). Updating R and packages can sometimes lead to unexpected issues, so it’s best to do it well in advance of when you need everything to work perfectly.
Nevertheless, even with these precautions, you may still encounter version-related issues from time to time. When this happens, don’t panic!
A common problem you might see is an error message when trying to install or load a package, indicating that the package requires a newer version of R or another package. The error / warning message might look like:
warning: package 'xyz' requires R version >= 4.2.0
Warning in install.packages: package ‘XYZ’ is not available (for R version 4.2.0)
These messages indicate that the package you are trying to install or load requires a newer version of R than the one you currently have. To fix this, you will need to update your R installation to the required version or higher. Then its also a good idea to update your packages as well.
Note
RStudio is also regularly updated, with new version released every several months or so. Your version of RStudio is independent of your version of R, so you can update RStudio without changing your R version. Note that usually your version of RStudio is not as important as your version of R and the packages you are using. So updating RStudio is usually not a high priority and doesn’t often help solve problems related to add on package versions.
R Projects
I always work within R Projects. R Projects help you to organise your work and keep all files related to a project in one place. They also make importing data a breeze.
But what is an R Project? An R Project is a directory (folder) that contains all the files related to a specific project. When you open an R Project, RStudio automatically sets the working directory to the project directory, so you don’t have to worry about setting the working directory manually.
To see if you’re working within an R Project, look at the top right of the RStudio window. If you see the name of your project there, you’re good to go. If you see “Project: (None)”, then you’re not working within an R Project.
If you click on the project name, a dropdown menu will appear. From there, you can create a new project, open an existing project, or switch between projects.
Create a new R Project: File > New Project > New Directory or Existing Directory > New Project > Choose a name and location for your project > Create Project.
Important
Get organised! Put all files for a project in one folder. For example, I made a folder called BIO144_2026 and put all files related to this course in that folder. Within that folder, I have subfolders for data, scripts, and results. I then create an R Project in the BIO144_2026 folder. This way, all files related to the course are in one place, and I can easily find them later.
Now, always open and ensure you’re working within the R Project for your project. As mentioned, you can see the project name at the top right of the RStudio window. And if its not the correct project, click on the name to get the drop-down list of available projects from which you can switch to the correct one.
Importing data
First, get some datasets for us to work with. The datasets used in this book are available for download as a zip file here: course_book_datasets.zip. You can download this file and unzip it to get all of the datasets used in the book. The datasets are in CSV format, which can be opened in R or other statistical software.
Put the datasets in a datafolder in your project folder.
We will use the readr package to import data into R. The readr package provides functions to read data from various file formats, including CSV (comma-separated values) files, tab-separated values files, and others.
To read a CSV file, we can use the read_csv() function from the readr package. For example, to read a CSV file called my_data_file.csv, we can use the following code:
library(readr)
my_data <- read_csv("datasets/my_data_file.csv")This code will read the data.csv file from the data folder within the current working directory (which should be the R Project directory) and store it in a data frame called data.
Tip
Easily getting the file path In RStudio, you can easily get the file path by putting the cursor in the parentheses of the read_csv() function, the press the tab key. A drop-down menu will appear with options to navigate to the file. This way, you don’t have to type the file path manually.
Viewing the data
Once you’ve imported your data, you can view it in several ways:
- Click on the data frame in the Environment tab in RStudio to open it in a new tab.
- Use the
View()function to open the data frame in a new tab in RStudio. - Use the
head()function to view the first few rows of the data frame. - Use the
str()function to view the structure of the data frame, including the variable names and types. - Use the
summary()function to get a summary of the data frame, including basic statistics for each variable.
Another useful function is glimpse() from the dplyr package, which provides a quick overview of the data frame.
library(dplyr)
glimpse(my_data)There are many checks you can do to ensure your data was imported correctly. For example checking if there are duplicated values in a variable when there shouldn’t be:
any(duplicated(my_data$Name))[1] FALSEThe function any() will return TRUE if there are any duplicated values in the Name variable, and FALSE otherwise. The function duplicated() returns a logical vector indicating which values are duplicates. We use the dollar sign $ to access a specific variable (column) in the data frame. A logical vector is a vector that contains only TRUE or FALSE values:
duplicated(my_data$Name)[1] FALSE FALSE FALSEAll three logicals are FALSE, meaning none of the three are duplicates. If there were duplicates, the corresponding positions in the logical vector would be TRUE. For example:
example_vector <- c("A", "B", "A", "C", "B")What do you expect the output of duplicated(example_vector) to be?
A final check (though not the final one we could do–there are many others). Let us check for missing values and get a count of how many there are in each variable. We can do this with the following tidyverse code:
library(tidyverse)
my_data |>
summarise(across(everything(), ~ sum(is.na(.)))) Name Age Height
1 0 0 0Looks complicated eh! Well, that’s because it is, for sure. But let’s break it down:
summarise()creates a new data frame with summary statistics.across(everything(), ~ sum(is.na(.)))applies the functionsum(is.na(.))to every variable in the data frame.- The
is.na()function returns a logical vector indicating which values are missing (NA), and thesum()function counts the number ofTRUEvalues in that vector (i.e., the number of missing values).
Important
Let’s assume your data was imported incorrectly. This means you have to inspect it carefully. Check that the variable names are correct, that the data types are correct (e.g., numeric, character, factor), that there are the correct number of rows and columns. If you find any issues, you need to find out what caused them, fix them, and re-import the data (see below).
Common data import problems:
- Incorrect delimiter: If your data file uses a different delimiter (e.g., tab, semicolon), you need to specify it in the
read_csv()function using thedelimargument (e.g.,read_delim("data.csv", delim = "\t")for tab-delimited files). - Missing values: If your data file uses a specific value to represent missing data (e.g., “NA”, “-999”), you need to specify it in the
read_csv()function using thenaargument (e.g.,read_csv("data.csv", na = c("NA", "-999"))). - Only one column: If your data file has only one column, it may be because the delimiter is incorrect. Check the delimiter and re-import the data with the correct delimiter.
- You opened the downloaded file in Excel and then saved it: Excel may have changed the format of the file when you opened and saved it. Always work with the original downloaded file.
- Wrong path or file name: Make sure the file path and name are correct. Remember, when you work in an R Project, you can place the cursor in the parentheses of the
read_csv()function and press the tab key to navigate to the file.
Data wrangling
Now we have our data imported and checked, and we’re ready to start working with it. This process is called data wrangling, and it involves cleaning, transforming, and reshaping the data to make it suitable for visualisation and analysis.
Clean the variable names
The first thing I like to do is standardise and clean up the variable names. I like to use the janitor package for this:
library(janitor)
Attaching package: 'janitor'The following objects are masked from 'package:stats':
chisq.test, fisher.testmy_data <- my_data |>
clean_names()The clean_names() function from the janitor package will convert variable names to a consistent format (lowercase, spaces replaced by underscores, no special characters).
Note
When we ran the code library(janitor) we got the message: Attaching package: ‘janitor’ The following objects are masked from ‘package:stats’: chisq.test, fisher.test This sometimes happens when two packages have functions with the same name. In this case, the janitor package has functions called chisq.test() and fisher.test(), which are also in the base stats package. When we load the janitor package, it masks (hides) the functions from the stats package. This is usually not a problem, but if you want to use the functions from the stats package, you can specify the package name when calling the function, like this: stats::chisq.test().
Manipulate the data frame
Functions in the dplyr package are used to manipulate data frames:
select(): select columns by position, or by name, or by other methodsfilter(): select rows that meet a logical conditionslice(): select rows by positionarrange(): reorder rowsmutate(): add new variables
The dplyr package also provides functions to group data frames and to summarize data:
group_by(): add to a data frame a grouping structuresummarize(): summarize data, respecting any grouping structure specified bygroup_by()
The pipe operator |> is used to chain together multiple operations on a data frame.
Tip
Note that you will often see another pipe operator %>% used in examples. The pipe operator |> is a newer version of %>% that is more efficient and easier to use. The pipe operator |> is available in R version 4.1.0 and later.
Lets work through some examples with a sample data frame:
my_data1 <- tibble(
name = c("Alice", "Bob", "Charlie", "David", "Eva"),
age = c(25, 30, 35, 40, 45),
score = c(90, 85, 95, 80, 70))Here is the same dataset with 100 rows:
set.seed(123)
my_data2 <- tibble(name = paste0("Person_", sprintf("%03d", 1:100)),
age = sample(20:50, 100, replace = TRUE),
score = rnorm(100, mean = 75, sd = 10))Select columns
We can select columns by name
my_data2 |>
select(name, score)# A tibble: 100 × 2
name score
<chr> <dbl>
1 Person_001 91.9
2 Person_002 87.3
3 Person_003 77.8
4 Person_004 64.5
5 Person_005 69.8
6 Person_006 91.2
7 Person_007 64.3
8 Person_008 91.9
9 Person_009 72.6
10 Person_010 70.3
# ℹ 90 more rowsWe can select columns by position
my_data2 |>
select(1, 3)# A tibble: 100 × 2
name score
<chr> <dbl>
1 Person_001 91.9
2 Person_002 87.3
3 Person_003 77.8
4 Person_004 64.5
5 Person_005 69.8
6 Person_006 91.2
7 Person_007 64.3
8 Person_008 91.9
9 Person_009 72.6
10 Person_010 70.3
# ℹ 90 more rowsWe can select columns by a condition, for example select only the numeric columns:
my_data2 |>
select(where(is.numeric))# A tibble: 100 × 2
age score
<int> <dbl>
1 50 91.9
2 34 87.3
3 38 77.8
4 33 64.5
5 22 69.8
6 29 91.2
7 37 64.3
8 41 91.9
9 30 72.6
10 24 70.3
# ℹ 90 more rowsWe can select a column by pattern matching, using helper functions, for example select columns that contain the letter “a”:
my_data2 |>
select(contains("a"))# A tibble: 100 × 2
name age
<chr> <int>
1 Person_001 50
2 Person_002 34
3 Person_003 38
4 Person_004 33
5 Person_005 22
6 Person_006 29
7 Person_007 37
8 Person_008 41
9 Person_009 30
10 Person_010 24
# ℹ 90 more rowsOther helpers include starts_with(), ends_with(), matches(), and everything().
Filter: Getting particular rows of data
To get particular rows of data, we can use the filter() function. This function takes a logical condition as an argument and returns only the rows that meet that condition. For example, to get all rows where the Age is greater than 30:
my_data2 |>
filter(age > 30)# A tibble: 66 × 3
name age score
<chr> <int> <dbl>
1 Person_001 50 91.9
2 Person_002 34 87.3
3 Person_003 38 77.8
4 Person_004 33 64.5
5 Person_007 37 64.3
6 Person_008 41 91.9
7 Person_011 39 67.3
8 Person_012 33 96.5
9 Person_013 41 61.7
10 Person_014 44 80.0
# ℹ 56 more rowsHere, the logical condition is age > 30.
We can combine multiple conditions using the logical operators & (and), | (or), and ! (not). For example, to get all rows where the Age is greater than 30 and the Score is less than 90:
my_data2 |>
filter(age > 30 & score < 90)# A tibble: 60 × 3
name age score
<chr> <int> <dbl>
1 Person_002 34 87.3
2 Person_003 38 77.8
3 Person_004 33 64.5
4 Person_007 37 64.3
5 Person_011 39 67.3
6 Person_013 41 61.7
7 Person_014 44 80.0
8 Person_015 45 87.3
9 Person_016 46 81.3
10 Person_018 38 82.9
# ℹ 50 more rowsOther logical operators include == (equal to), != (not equal to), <= (less than or equal to), and >= (greater than or equal to).
Slice: Getting rows by position
The slice() function allows us to get rows by their position in the data frame. For example, to get the first two rows:
my_data2 |>
slice(1:2)# A tibble: 2 × 3
name age score
<chr> <int> <dbl>
1 Person_001 50 91.9
2 Person_002 34 87.3I very rarely use this function, as I prefer to use filter() with logical conditions. I can’t think of a good use case for this function right now! Perhaps you can?
Arrange: Reordering rows
The arrange() function allows us to reorder the rows of a data frame based on the values in one or more columns. For example, to reorder the rows by Age in ascending order:
my_data2 |>
arrange(age)# A tibble: 100 × 3
name age score
<chr> <int> <dbl>
1 Person_064 20 88.8
2 Person_056 21 79.5
3 Person_091 21 67.4
4 Person_005 22 69.8
5 Person_025 22 74.9
6 Person_033 23 67.3
7 Person_092 23 72.4
8 Person_010 24 70.3
9 Person_017 24 79.1
10 Person_058 24 72.7
# ℹ 90 more rowsI f we want to reorder the rows by Age in descending order, we can use the desc() function:
my_data2 |>
arrange(desc(age))# A tibble: 100 × 3
name age score
<chr> <int> <dbl>
1 Person_001 50 91.9
2 Person_061 50 79.9
3 Person_075 50 67.3
4 Person_085 50 50.1
5 Person_096 50 86.8
6 Person_031 49 71.8
7 Person_078 49 72.6
8 Person_024 48 81.2
9 Person_057 48 80.3
10 Person_021 47 66.0
# ℹ 90 more rowsIt’s unusual to need the rows of a dataset to be arranged in a specific order, but it can be useful when looking at the data directly.
Tip
Note that when you view the data in RStudio, it will always be arranged by the row number. In the viewer you can sort by clicking on the column headers.
Mutate: Adding new variables
The mutate() function allows us to add new variables to a data frame. For example, to add a new variable called Age_in_5_years that is the Age plus 5:
my_data2 |>
mutate(age_in_5_years = age + 5)# A tibble: 100 × 4
name age score age_in_5_years
<chr> <int> <dbl> <dbl>
1 Person_001 50 91.9 55
2 Person_002 34 87.3 39
3 Person_003 38 77.8 43
4 Person_004 33 64.5 38
5 Person_005 22 69.8 27
6 Person_006 29 91.2 34
7 Person_007 37 64.3 42
8 Person_008 41 91.9 46
9 Person_009 30 72.6 35
10 Person_010 24 70.3 29
# ℹ 90 more rowsWe can add multiple new variables at once:
my_data2 |>
mutate(
age_in_5_years = age + 5,
percentage_score = score / 100
)# A tibble: 100 × 5
name age score age_in_5_years percentage_score
<chr> <int> <dbl> <dbl> <dbl>
1 Person_001 50 91.9 55 0.919
2 Person_002 34 87.3 39 0.873
3 Person_003 38 77.8 43 0.778
4 Person_004 33 64.5 38 0.645
5 Person_005 22 69.8 27 0.698
6 Person_006 29 91.2 34 0.912
7 Person_007 37 64.3 42 0.643
8 Person_008 41 91.9 46 0.919
9 Person_009 30 72.6 35 0.726
10 Person_010 24 70.3 29 0.703
# ℹ 90 more rowsGrouping and summarising data
The group_by() function allows us to add a grouping structure to a data frame, and the summarise() function allows us to summarise the data, respecting any grouping structure specified by group_by().
First let us read in a dataset to work with. The dataset is simulated about factors that could be associated with blood pressure
Study design:
- 60 individuals
- Sex assigned at birth: Male / Female
- Treatment: Placebo / Drug
- Exercise program: Yes / No
- Four visits (repeated measures per person)
- Age varies between individuals
- Outcome: systolic blood pressure (mmHg)
Read in and view the data:
bp_multifactor <- read_csv("datasets/bp_multifactor.csv")Rows: 240 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): sex, treatment, exercise
dbl (4): id, age, visit, systolic_bp
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.glimpse(bp_multifactor)Rows: 240
Columns: 7
$ id <dbl> 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5…
$ sex <chr> "Female", "Female", "Female", "Female", "Female", "Female"…
$ treatment <chr> "Drug", "Drug", "Drug", "Drug", "Drug", "Drug", "Drug", "D…
$ exercise <chr> "No", "No", "No", "No", "No", "No", "No", "No", "Yes", "Ye…
$ age <dbl> 57, 57, 57, 57, 47, 47, 47, 47, 35, 35, 35, 35, 54, 54, 54…
$ visit <dbl> 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4…
$ systolic_bp <dbl> 133.2036, 136.9701, 122.2254, 120.0836, 130.7802, 126.2976…First, a simple summarise. We will get the mean blood pressure across all visits and all people:
bp_multifactor |>
summarise(mean_bp = mean(systolic_bp))# A tibble: 1 × 1
mean_bp
<dbl>
1 131.How does this work? The summarise() function creates a new data frame with summary statistics. The argument mean_bp = mean(systolic_bp) calculates the mean of the systolic_bp variable and names it mean_bp. (The mean of all the observations is sometimes called the “grand mean”.)
Now let’s get the mean blood pressure for each person. To do this, we need to tell the summarise to calculate the mean for each person. We can do this by adding a grouping structure to the data frame with the group_by() function:
bp_multifactor |>
group_by(id) |>
summarise(mean_bp = mean(systolic_bp))# A tibble: 60 × 2
id mean_bp
<dbl> <dbl>
1 1 128.
2 2 127.
3 3 127.
4 4 137.
5 5 128.
6 6 118.
7 7 133.
8 8 120.
9 9 128.
10 10 119.
# ℹ 50 more rowsThe group_by(id) function adds a grouping structure to the data frame based on the id variable. This tells the summarise() function to calculate the mean blood pressure for each person (i.e., for each unique value of id).
We can see the grouping structure when we look at the output of the group_by() function:
bp_multifactor |>
group_by(id)# A tibble: 240 × 7
# Groups: id [60]
id sex treatment exercise age visit systolic_bp
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 1 Female Drug No 57 1 133.
2 1 Female Drug No 57 2 137.
3 1 Female Drug No 57 3 122.
4 1 Female Drug No 57 4 120.
5 2 Female Drug No 47 1 131.
6 2 Female Drug No 47 2 126.
7 2 Female Drug No 47 3 120.
8 2 Female Drug No 47 4 132.
9 3 Male Drug Yes 35 1 133.
10 3 Male Drug Yes 35 2 132.
# ℹ 230 more rowsThe output has the line # Groups: id [60], which indicates that the data frame is now grouped by the id variable, and there are 60 unique groups (i.e., 60 people).
It is that simple :)
We can simultaneously group by multiple variables. For example, to get the mean blood pressure for each combination of sex and treatment. Before we do this, we can check how many unique combinations we think we should have. We already know there are two sexes and two treatments (Placebo and Drug), so we should have four unique combinations, and therefore four means.
bp_multifactor |>
group_by(sex, treatment) |>
summarise(mean_bp = mean(systolic_bp))`summarise()` has grouped output by 'sex'. You can override using the `.groups`
argument.# A tibble: 4 × 3
# Groups: sex [2]
sex treatment mean_bp
<chr> <chr> <dbl>
1 Female Drug 126.
2 Female Placebo 134.
3 Male Drug 132.
4 Male Placebo 138.Perfect.
We can also calculate multiple summary statistics at once. For example, to get the mean and standard deviation of blood pressure for each combination of sex and treatment:
bp_multifactor |>
group_by(sex, treatment) |>
summarise(
mean_bp = mean(systolic_bp),
sd_bp = sd(systolic_bp)
)`summarise()` has grouped output by 'sex'. You can override using the `.groups`
argument.# A tibble: 4 × 4
# Groups: sex [2]
sex treatment mean_bp sd_bp
<chr> <chr> <dbl> <dbl>
1 Female Drug 126. 8.55
2 Female Placebo 134. 6.90
3 Male Drug 132. 7.41
4 Male Placebo 138. 7.70Working with categorical variables
Variables in a data frame in R have a type. The most common types of variables are numeric and categorical. Numeric variables are variables that take on numerical values, such as age or score. Categorical variables are variables that take on a limited number of values, often representing categories or groups. In R, categorical variables are typically have type <chr> which is character. Or they can be of type <fct> which is factor.
When we import data categorical variable is usually imported as a character variable. For example, the variable name in our example dataset is a categorical variable of type character. Look at the first few rows of the dataset again, and see that below the variable name it says <chr> for the name variable:
my_data2# A tibble: 100 × 3
name age score
<chr> <int> <dbl>
1 Person_001 50 91.9
2 Person_002 34 87.3
3 Person_003 38 77.8
4 Person_004 33 64.5
5 Person_005 22 69.8
6 Person_006 29 91.2
7 Person_007 37 64.3
8 Person_008 41 91.9
9 Person_009 30 72.6
10 Person_010 24 70.3
# ℹ 90 more rowsThis is all totally fine. There are, however, use cases where we might want to convert a character variable to a factor variable. Factors are useful when we have a categorical variable with a fixed number of levels, and we want to specify the order of those levels. For example, if we had a variable called education_level with the values “High School”, “Bachelor’s”, “Master’s”, and “PhD”, we might want to convert this variable to a factor and specify the order of the levels.
Let’s make a new dataset to illustrate this:
my_data3 <- tibble(
name = c("Alice", "Bob", "Charlie", "David", "Eve"),
education_level = c("Bachelor's", "Master's", "PhD", "High School", "Bachelor's"),
age = c(19, 23, 25, 16, 20)
)Look at the structure of this new dataset:
my_data3# A tibble: 5 × 3
name education_level age
<chr> <chr> <dbl>
1 Alice Bachelor's 19
2 Bob Master's 23
3 Charlie PhD 25
4 David High School 16
5 Eve Bachelor's 20We can see that the education_level variable is of type <chr>, which is character.
We can convert the education_level variable to a factor:
my_data3 <- my_data3 |>
mutate(education_level = factor(education_level))
my_data3# A tibble: 5 × 3
name education_level age
<chr> <fct> <dbl>
1 Alice Bachelor's 19
2 Bob Master's 23
3 Charlie PhD 25
4 David High School 16
5 Eve Bachelor's 20Now, the education_level variable is of type <fct>, which is factor.
Here is a graph of age by education level:
ggplot(my_data3, aes(x = education_level, y = age)) +
geom_point()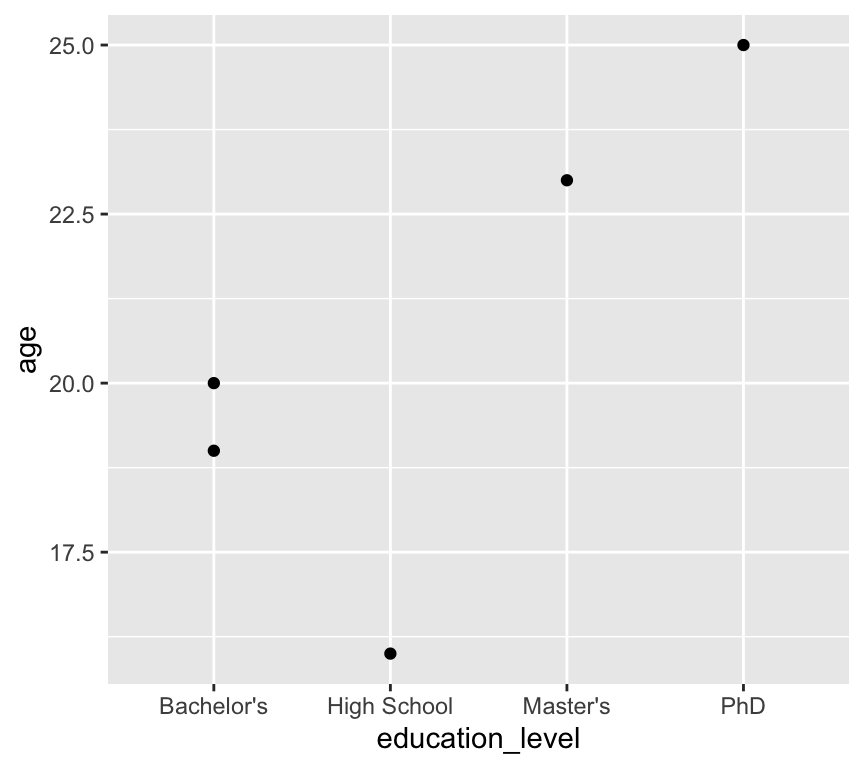
We have a problem here: the education levels are not in a sensible order. The first level is “Bachelor’s”, followed by “High School”, “Master’s”, and “PhD”.
Note
Why do you think the levels are in this order? We didn’t tell R to order them like this! The answer is that R orders factor levels alphabetically by default. So when we convert a character variable to a factor without specifying the order of the levels, R will order them alphabetically.
It would be much better to have the levels ordered as “High School”, “Bachelor’s”, “Master’s”, and “PhD”.
We can fix this by specifying the order of the levels when we convert the variable to a factor:
my_data3 <- my_data3 |>
mutate(education_level = factor(education_level,
levels = c("High School", "Bachelor's", "Master's", "PhD")))Now when we plot the data again, the education levels are in the correct order:
ggplot(my_data3, aes(x = education_level, y = age)) +
geom_point()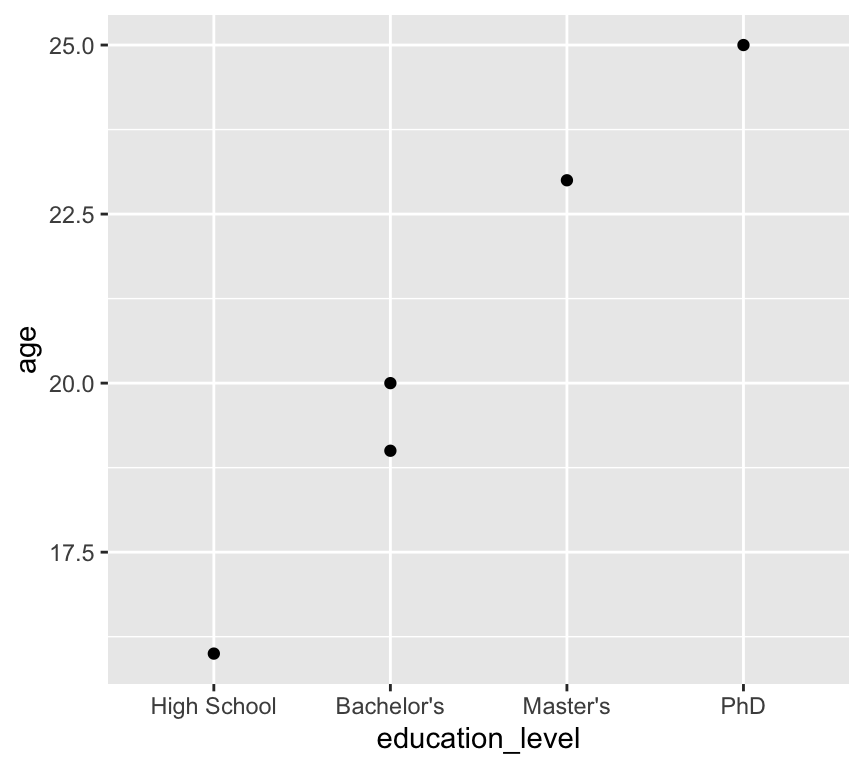
Another use case is when we are making a linear model and want to specify the reference level for a categorical variable. We will look at this when we get to linear models. If you want to skip ahead, you can see how this works in a section at the end of this chapter.
Visualisation
There are many many many types of data visualisation. We will not explore them all in this course! In fact, we will use only a few basic types of visualisation, but we will use them well and critically. The three types of visualisation we will focus on are scatter plots, histograms, and box and whisker plots.
Three basic types of visualisation
Scatterplots are used to visualise the relationship between two continuous variables. Here is an example of a scatterplot:
library(ggplot2)
ggplot(my_data2, aes(x = age, y = score)) +
geom_point()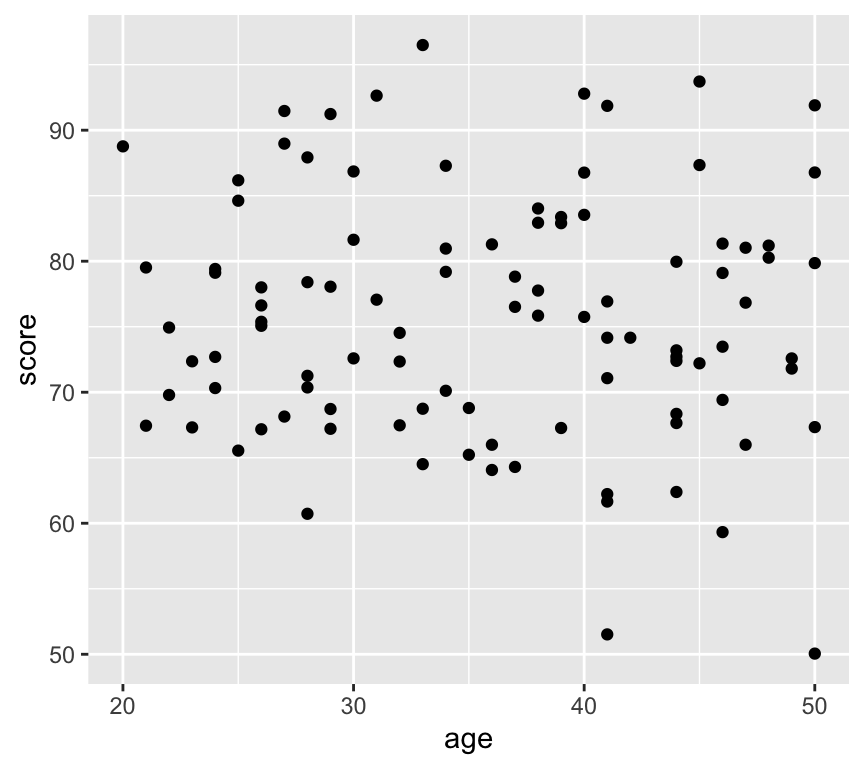
Histograms are used to visualise the distribution of a single continuous variable. The axiss are different to scatterplots: the x-axis is the variable being measured, and the y-axis is the count (or frequency) of observations in each bin. A bin is a range of values. Here is an esample of a histogram:
ggplot(my_data2, aes(x = score)) +
geom_histogram(bins = 10)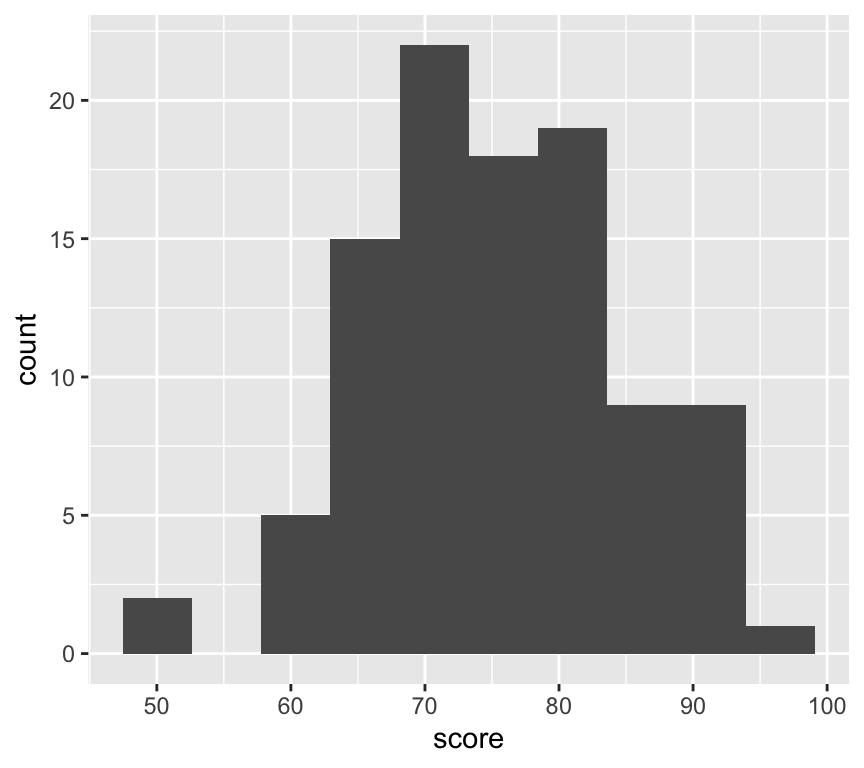
Box and whisker plots are used to visualise the distribution of a continuous variable across different categories. Here is an example of a box and whisker plot. First we add a new variable that is age group:
my_data2 <- my_data2 |>
mutate(age_group = case_when(
age < 30 ~ "20-29",
age >= 30 & age < 40 ~ "30-39",
age >= 40 ~ "40-49"
))The new variable age_group is a categorical variable with three levels: “20-29”, “30-39”, and “40-49”. We make this using the case_when() function. This function works by checking each condition (which are given as the arguments to the function) in turn, and assigning the corresponding value when the condition is true. Now we can make the box and whisker plot:
ggplot(my_data2, aes(x = factor(age_group), y = score)) +
geom_boxplot()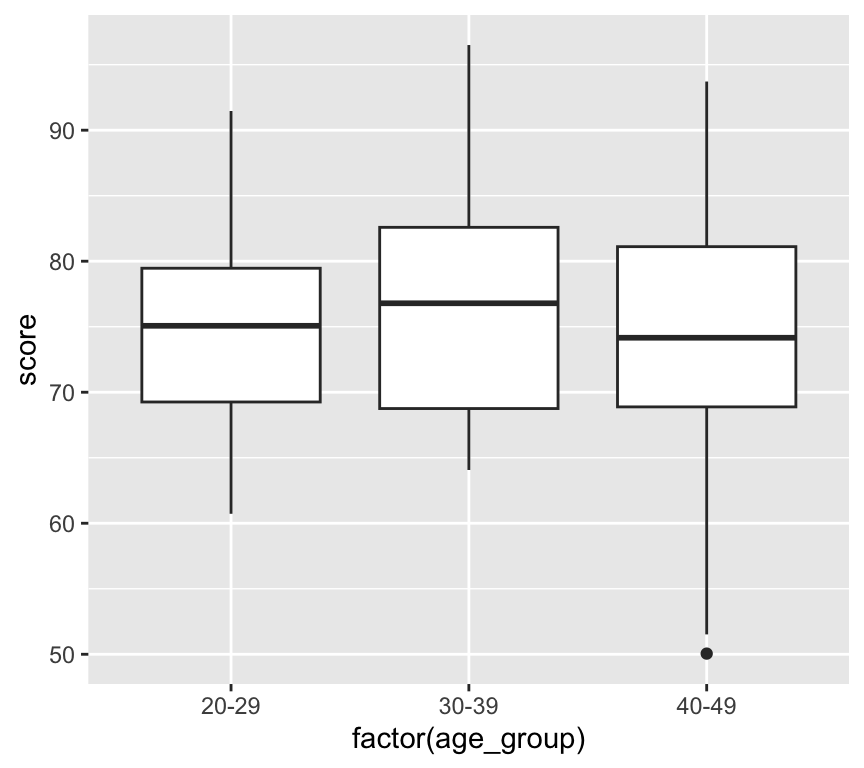
Understanding ggplot2 syntax
We have used the ggplot2 package to create visualisations. The ggplot2 package is based on the grammar of graphics, which provides a consistent way to create visualisations. It is amazing, and when it was created it revolutionised data visualisation in R.
You can see that for each of the three visualisations, we use the ggplot() function to create the base plot, and then we add layers to the plot using the + operator.
The first argument to the ggplot() function is the data frame that we want to visualise. The layers that we add to the plot each have two main components. The first component is the aesthetic mappings, which specify how the variables in the data frame are mapped to the visual properties of the plot (e.g., x-axis, y-axis, color, size). The second component is the geometric object, which defines how the data is represented in the plot (e.g., points, lines, bars).
The aesthetic mappings are specified using the aes() function, which takes arguments that define the mappings. Inside the aes() function, we specify the variables from the data frame that we want to map to the visual properties of the plot. For example, in the scatterplot, we map the age variable to the x-axis and the score variable to the y-axis using aes(x = age, y = score).
The geometric object is specified using functions that start with geom_, such as geom_point(), geom_histogram(), and geom_boxplot().
You will notice that for the scatterplot and the box and whisker plot, we specify both an x- and a y-variable, but for the histogram we only specify an x-variable. This is because histograms only have one variable, which is the variable being measured. The y-axis is automatically calculated as the count (or frequency) of observations in each bin.
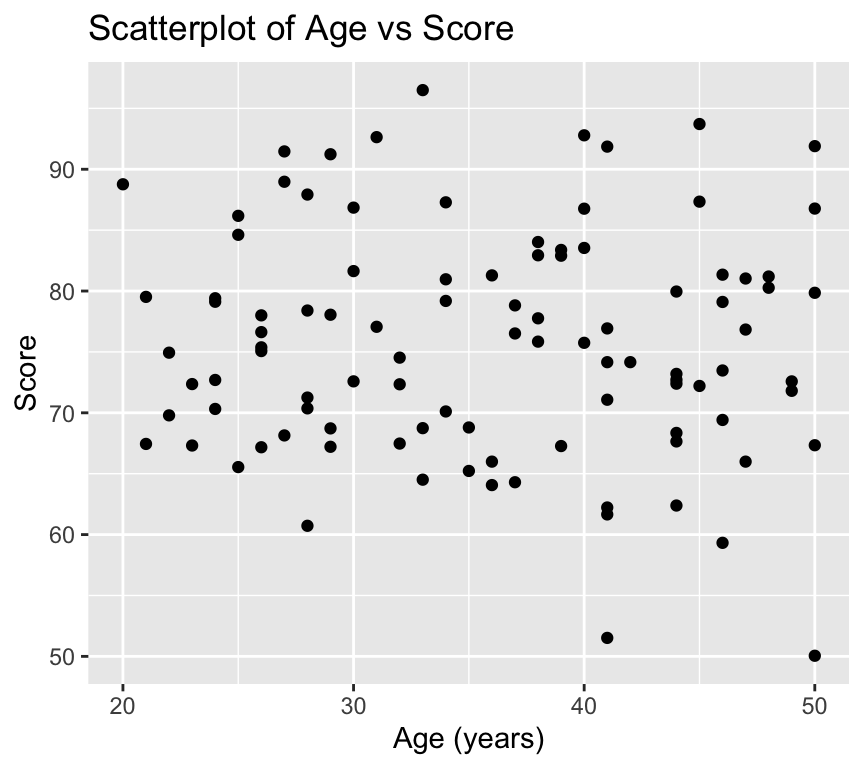
We can customise many features of the graph using additional arguments to the ggplot() function and the geom_ functions. For example, we can add titles and labels to the axes using the labs() function:
ggplot(my_data2, aes(x = age, y = score)) +
geom_point() +
labs(
title = "Scatterplot of Age vs Score",
x = "Age (years)",
y = "Score"
)
We can also change the theme of the plot using the theme_ functions. For example, to use a minimal theme, and add it the customisations we already made:
ggplot(my_data2, aes(x = age, y = score)) +
geom_point() +
labs(
title = "Scatterplot of Age vs Score",
x = "Age (years)",
y = "Score"
) +
theme_minimal()
There are a million and one ways to customise visualisations in ggplot2. We will explore many of them during the course in a rather ad-hoc way. In this course we do not assess your skill and competence in making clear and beautiful visualisations. We will, however, be very happy to help you make beautiful and effective visualisations for your assignments and projects. And please be sure that making beautiful and effective visualisations is a skill that is very highly valued in the workplace.
Saving ggplot visualisations
Another feature that is very useful is to save ggplot visualisations to objects and then save to a file (for example a pdf). First, here is how we save a ggplot to an object:
plot1 <- ggplot(my_data2, aes(x = age, y = score)) +
geom_point() +
labs(
title = "Scatterplot of Age vs Score",
x = "Age (years)",
y = "Score"
) Now we can save the plot to a file using the ggsave() function:
ggsave("scatterplot_age_vs_score.pdf", plot = plot1, width = 8, height = 6)Note two things about the ggsave() function. First, the first argument is the file name (including the file extension). The file extension determines the file type (e.g., pdf, png, jpeg). Second, we can specify the width and height of the plot in inches.
Also note that the file is saved to the current working directory. When you’re working in an R project, this is usually the base directory of the project. If you want to save your plots in a folder named plots you would first need to create the folder (if it doesn’t already exist) and then specify the path in the file name:
dir.create("plots") # Create the folder if it doesn't existWarning in dir.create("plots"): 'plots' already existsggsave("plots/scatterplot_age_vs_score.pdf", plot = plot1, width = 8, height = 6)Review
In this chapter we learned about using R and RStudio for data analysis. We covered the basics of R programming, including data types, variables, functions, and control structures. We also learned about importing data into R, cleaning and wrangling data using the dplyr package, and visualising data using the ggplot2 package. A great starting point for your journey into data analysis with R!
Further reading
The data wrangling packages we use, such as dplyr and tidyr, are part of the tidyverse, a collection of R packages designed for data science. These packages were developed by Hadley Wickham and his team at RStudio. Moreover, Hadley Wickham is also the creator of ggplot2, the package we use for data visualisation.
A great place to consolidate your learning so far, and to learn more about the tidyverse and data science with R is the book R for Data Science by Hadley Wickham and Garrett Grolemund (https://r4ds.had.co.nz/). This book is available for free online and covers many topics related to data science with R, including:
- Scripts and projects
- Data import
- Data wrangling with dplyr and tidyr
- Data visualisation with ggplot2
- And much more…
Base R is a term used to describe the core functionality of R, without any additional packages. While the tidyverse packages are very useful and powerful, it can be useful to learn about the base R functions, especially if someone else is using base R in their code. A starting point for learning about base R is the chapter “A field guide to base R” in the R for Data Science book – A field guide to base R.
Cheat sheets
There are a series of excellent cheat sheets for R and RStudio, and for packages in the tidyverse. They’re pretty dense and packed with information, but they can be very useful as a quick reference. You can find them here: RStudio Cheat Sheets.
Extras
Joining data frames
In this chapter we have only worked with one data frame at a time. However, in real life you will often have multiple data frames that you need to join together. For example, you might have one data frame with demographic information about people (e.g., age, sex, education level) and another data frame with information about their health outcomes (e.g., blood pressure, cholesterol levels). You can use the dplyr package to join these data frames together using functions like left_join(), right_join(), inner_join(), and full_join(). We won’t cover these during the course, but you can read about them in the R for Data Science book – Joining data frames.
Making reports directly using Quarto
We don’t explicitly ask you to make reports using Quarto in this course, but it is a very useful skill to have, and I highly recommend you explore it further in your own time. Here are a few basics to get you started.
One of the great features of R and RStudio is the ability to create reports that combine text, code, and visualisations. One of the most popular tools for this is Quarto (https://quarto.org/), which allows you to create documents in various formats (HTML, PDF, Word, etc.) using a combination of Markdown and R code.
**Why is this so great???* If you want to show someone your analysis and visualisation, say a team member or supervisor, it is often good to prepare a report that explains what you did, perhaps shows the code you used, and presents the results (including visualisations). One way to go about this is to prepare a powerpoint presentation or a word document, and then copy and paste code and visualisations into the document. Its what I used to do. It works. But it is tedious, error prone, and when you change something in your code or data, you have to remember to go back and update the powerpoint or word document.
With Quarto, you can create a report that automatically includes the code and visualisations directly from your R script. This way, if you change the code or data, you can simply re-render the report and everything is automatically updated. It takes away a lot of the tediousness and potential for errors. And it makes updating reports much easier.
If you’d like to get started with Quarto, check out the Quarto website (https://quarto.org/) and the RStudio Quarto documentation (https://quarto.org/docs/get-started/). There are also many tutorials and resources available online to help you learn how to use Quarto effectively.
If you have questions about Quarto, feel free to ask me or TAs during the practicals, though note that any particular TAs may or may not be experienced with Quarto themselves.
Quarto reports are also covered in the R for Data Science book – Quarto.
Mathematical notation in ggplot2
When creating visualisations with ggplot2, you may want to include mathematical notation in your titles, axis labels, or legends. This can be done using the latex2exp package, which allows you to use LaTeX syntax to create mathematical expressions in your plots. Here is an example of how to use latex2exp to include mathematical notation in a ggplot:
ggplot(mapping = aes(x = 1, y = 1)) +
geom_point() +
labs(x = latex2exp::TeX("Movement speed ($µm$ $sec^{-1}$)"),
y = latex2exp::TeX("Distance moved ($µm$)"),
title = latex2exp::TeX("Relationship between movement speed and distance moved"))
Combining ggplots with patchwork
We often make multiple ggplots in our analyses. Sometimes it is useful to combine multiple plots into a single figure for easier comparison or presentation. We can do with ggplots and the lovely add-on package called patchwork. The patchwork package allows us to combine multiple ggplots into a single plot layout. Here is an example of how to use patchwork to combine the three plots we made earlier (scatterplot, histogram, and boxplot):
First, load the patchwork package:
library(patchwork)Next make the first plot and assign it to an object:
plot1 <- ggplot(my_data2, aes(x = age, y = score)) +
geom_point() +
labs(
title = "Scatterplot of Age vs Score",
x = "Age (years)",
y = "Score"
) Now make the second plot and assign it to an object:
plot2 <- ggplot(my_data2, aes(x = score)) +
geom_histogram(binwidth = 5) +
labs(
title = "Histogram of Scores",
x = "Score",
y = "Count"
) Now make the third plot and assign it to an object:
plot3 <- ggplot(my_data2, aes(x = factor(age_group), y = score)) +
geom_boxplot() +
labs(
title = "Boxplot of Scores by Age Group",
x = "Age Group",
y = "Score"
) Now we can combine the three plots into a single layout using the patchwork syntax. Here, we arrange plot1 on the top row, and plot2 and plot3 side by side on the bottom row:
combined_plot <- plot1 / (plot2 | plot3)
combined_plot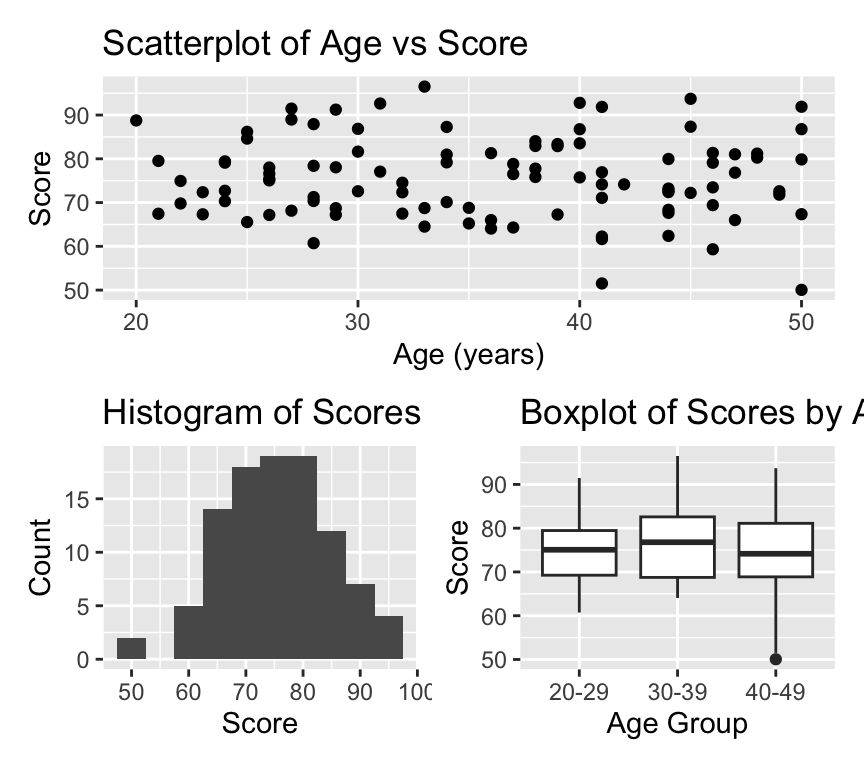
Amazing eh! OK, lets leave it there for now. We’ll use ggplot2 throughout the course, and explore more features as we go along.
If you’d like to read more about the patchwork package, check out the package website – patchwork.
Setting a reference level in a linear model
Sometimes when fitting linear models with categorical explanatory (independent) variables, it is useful to set a specific reference level for the categorical variable. This can help in interpreting the model coefficients. In R, we can set the reference level using the relevel() function or by using the factor() function with the levels argument.
First, let’s create a simple dataset:
my_data4 <- tibble(
treatment = factor(c("Control", "Aspirin", "Ibuprofen", "Control", "Aspirin", "Ibuprofen")),
response = c(5, 7, 6, 4, 8, 7)
)By default, R will set the first level of the factor (in alphabetical order) as the reference level. In this case, “Aspirin” would be the reference level. Therefore when we visualise the data:
ggplot(my_data4, aes(x = treatment, y = response)) +
geom_point() +
labs(
title = "Response by Treatment",
x = "Treatment",
y = "Response"
) 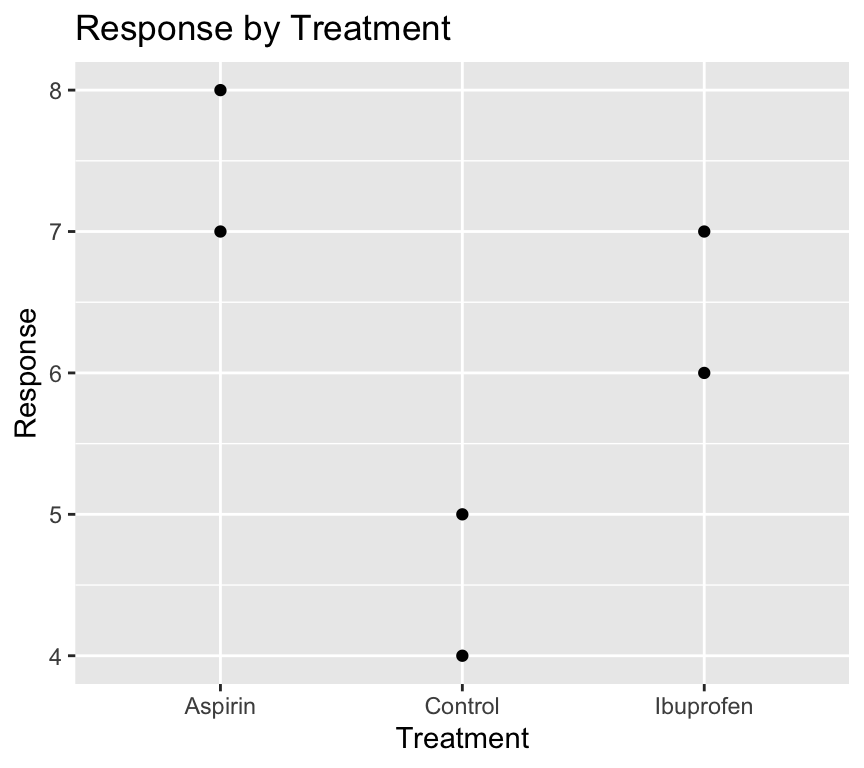
It would be nicer to have the “Control” group as the first level on the left of the x-axis.
Likewise, when we make a linear model:
model1 <- lm(response ~ treatment, data = my_data4)
summary(model1)
Call:
lm(formula = response ~ treatment, data = my_data4)
Residuals:
1 2 3 4 5 6
0.5 -0.5 -0.5 -0.5 0.5 0.5
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.5000 0.5000 15.000 0.000643 ***
treatmentControl -3.0000 0.7071 -4.243 0.023981 *
treatmentIbuprofen -1.0000 0.7071 -1.414 0.252215
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7071 on 3 degrees of freedom
Multiple R-squared: 0.8615, Adjusted R-squared: 0.7692
F-statistic: 9.333 on 2 and 3 DF, p-value: 0.05152The (Intercept) term corresponds to the “Aspirin” group, and the coefficients for “Control” and “Ibuprofen” are relative to “Aspirin”. R has done this because in the factor levels, “Aspirin” comes first alphabetically and was therefore set as the reference level when the factor variable was created.
If we want to set “Control” as the reference level, we can do so using relevel():
my_data4 <- my_data4 %>%
mutate(treatment = relevel(treatment, ref = "Control"))Now when we visualise the data again:
ggplot(my_data4, aes(x = treatment, y = response)) +
geom_point() +
labs(
title = "Response by Treatment",
x = "Treatment",
y = "Response"
) 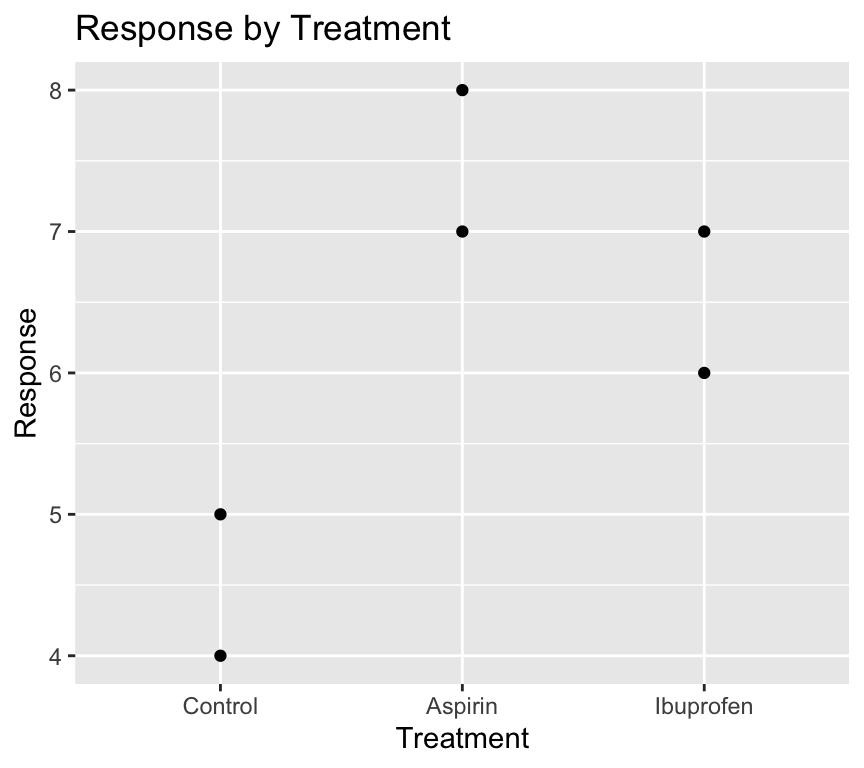
Magic! The “Control” group is now the first level on the left of the x-axis.
And when we fit the linear model again:
model2 <- lm(response ~ treatment, data = my_data4)
summary(model2)
Call:
lm(formula = response ~ treatment, data = my_data4)
Residuals:
1 2 3 4 5 6
0.5 -0.5 -0.5 -0.5 0.5 0.5
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.5000 0.5000 9.000 0.0029 **
treatmentAspirin 3.0000 0.7071 4.243 0.0240 *
treatmentIbuprofen 2.0000 0.7071 2.828 0.0663 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7071 on 3 degrees of freedom
Multiple R-squared: 0.8615, Adjusted R-squared: 0.7692
F-statistic: 9.333 on 2 and 3 DF, p-value: 0.05152The (Intercept) term now corresponds to the “Control” group, and the coefficients for “Aspirin” and “Ibuprofen” are relative to “Control”. This makes interpretation of the model coefficients more intuitive.
Also see the chapter about factors in the R for Data Science book – Factors.
Finding observations with extreme values
Imagine we have a dataset about people’s ages and their blood pressure, so that the dataset has three variables: id, age, and blood_pressure. We might want to find the id of people with extreme values of blood pressure, or age. How can we do this? And do this using code?
The first step is to define a criterion for what we consider to be an extreme value. For example, we might define an extreme value as being more than 3 standard deviations away from the mean. This is equivalent to saying that we define extreme value as ones with a z-score greater than 3 or less than -3. Here, a z-score is calculated as (value - mean) / standard deviation.
Let’s do this in code, and make the code as general (i.e., works for other datasets) as possible. Let’s say our dataset is called my_data, and it has three variables: ID, and two other variables
my_data |>
pivot_longer(cols = !matches("ID"),
names_to = "var_name",
values_to = "var_value") |>
group_by(var_name) |>
mutate(temp = var_value - mean(var_value),
z_val = temp / sd(temp)) |>
filter(z_val < -3 | z_val > 3) |>
pull(ID) |>
unique()How does this work?
First, we use pivot_longer() to reshape the data from wide format to long format. This allows us to work with all the variables (except ID) in a consistent way. The matches("ID") function is used to specify that we want to keep the ID variable as is, and pivot the other variables.
Second, we use group_by(var_name) to group the data by variable name. This allows us to calculate the mean and standard deviation for each variable separately.
Third, we use mutate() to calculate the z-score for each value of each variable. We first calculate the difference between the value and the mean (temp), and then divide by the standard deviation to get the z-score (z_val).
Fourth, we use filter() to keep only the rows where the z-score is less than -3 or greater than 3, which corresponds to our definition of extreme values.
Finally, we use pull(ID) to extract the ID variable from the filtered data, and unique() to get the unique IDs of people with extreme values.